Indexing has always been considered a highly targeted science. Enter a search query into Google search and the pages that are displayed are generally optimized towards that exact word or term. However, in their continual battle to server the most relevant but most natural pages with genuinely useful information Google has injected latent semantic indexing (LSI) into its algorithms.
What Is LSI?
LSI is a unique indexing method that potentially takes Google search one step closer to becoming human in its way of thinking. If we were to manually search through web pages to find information related to a given search term we would be likely to generate our own results based on the theme of the site, rather than whether a word exists or doesn't exist on the page.
Why Search Engines Might Adopt Latent Semantic Indexing
The extremely rigid form of "keyword indexing" also meant that black hat SEO techniques were easier to implement. Search engines could be manipulated into ranking a site highly by using set formula. Originally, cramming a page with a particular keyword or set of keywords meant a site would rank highly for that search term. The proceeding set of algorithms ensured that your link profile played more of an important part than your keyword density. Reciprocal linking soon followed once again making it possible to manipulate the search engine spiders by exchanging links with tens, hundreds, or thousands of websites.
Reciprocal linking was soon beaten as Google and to a lesser extent Yahoo and MSN gave less credence to a reciprocal link as they did to a one-way inbound link. Latent Semantic Indexing is another, particularly powerful, method to try and make their result pages appear more natural with natural pages filled with natural content.
The Effects
The introduction of LSI has seen some dramatic changes in the search engine result pages already. Sites that had previously performed well because of an impressive link profile based on a single keyword have found their pages slip in the rankings. Other pages with a more diverse portfolio of inbound links are taking the lead with search terms for which they had not previously performed.
SEO is far from dead because of LSI, in fact if anything, it has probably increased the need for professional white-hat SEO on your website. The field of SEO, though, has almost certainly changed. Website content copywriting for Google's benefit is not merely made up of keyword density and keyword placement as it once was and link-building techniques will need to change to incorporate LSI algorithms but it can be done.
Writing Content For LSI
If optimizing solely for Google then a web page can, theoretically, be naturally written and naturally worded. When we write we instinctively include the appropriate keyword in our text. In order to avoid repetition (or keyword optimization, as it was once called) we would often alter some instances of these keywords for other words with the same or very similar meaning. We naturally include the plural or singular form of a keyword as well as different tenses and a number of different stems of that keyword. In the eyes of LSI algorithms this is all good news.
Looking At Your Link Profile
A link profile should no longer consist of thousands of links with the same anchor text (that of your primary keyword). There's no reason to panic if you already have this kind of profile. Instead you should look at relevant and similar terms and improve your link profile by gaining links using these as your anchor text.
What It Offers Web Searchers
From the point of view of web searchers, LSI offers some distinct advantages over its earlier form of indexing. For example, LSI recognizes that the word "engine" in "search engine optimization" is not related to searches for terms like "steam engine" or "locomotive engine" and is instead related to Internet marketing topics. In theory, LSI results give a much more accurate page of results as well as providing a broader range of pages still geared towards a particular topic.
Where Google Leads, Others Generally Follow
It is widely acknowledged that Google is the search engine at the forefront of latent semantic indexing. On the whole they try to generate results pages that are literally filled with genuine, useful results and LSI certainly provides another string in their bow. Yahoo and MSN, for now, seem more than happy to go along with keyword specific indexing although Yahoo are known to look at singular and plural keyword variations as well as keyword stemming when judging keyword density.
The Effect On Your Website
How it affects the individual Webmaster is dependent on how they go about promoting their site already. If the pages are filled with natural content including keywords and keyword alternatives, and the link profile is similarly diversified for a number of related keywords then the fact is it won't change very much. However, if all of your efforts have been concentrated, either on-page or off-page, with a single keyword then it's time to readdress the balance.
About the Author:
Matt Jackson is a homepage content author for WebWiseWords. WebWiseWords specializes in natural web content writing that appeals to search engine spiders and to human visitors.
Tuesday, December 26, 2006
Friday, December 22, 2006
Matt Cutts: Website Reviews, Duplicate Content
by: Matt Cutts: Gadgets, Google, and SEO
I woke up early on Thursday and was at the convention center by 8am to check on my backpack and laptop. It was still tucked away under a table, untouched. Whew! I hunkered down in the speaker room and started working on my slides. (I hate seeing the same presentations over and over again at conferences, so I always try to make a new presentation for each show.)
By 9am, I was still really behind, so I decided to skip Danny’s keynote and kept chugging. I missed a few other sessions on Thursday, but I figured it was worth it to be prepared.
Around 1:30, Brett had signed me up for a site review panel with Greg Boser, Tim Mayer, Danny Sullivan, and Todd Friesen, with Jake Baillie moderating. The idea behind a site review panel is that people volunteer their sites and get advice on how to do things better. We discussed a promotional gifts company, the Dollar Stretcher site, a real estate company in Las Vegas, a chiropractic doctor, a real estate licensing company, a computer peripheral site, a hifi sounds store, and a day spa in Arizona. In his PubCon recap, Barry said I ripped on sites. For most of the sites I tried to give positive advice, but I wasn’t afraid to tell people of potential problems.
Once again, I sat on the end and had my wireless and VPN working so that I could use all of my Google tools. The promotional gifts company had a couple issues. For one thing, I was immediately able to find 20+ other sites also belonged to the promotional gifts person. The other sites offered overlapping content and overlapping pages on different urls. The larger issue was searching for a few words from a description quickly found dozens of other sites with the exact same descriptions. We discussed the difficulty of adding value to feeds when you’re running lots of sites. One thing to do is to find ways to incorporate user feedback (forums, reviews, etc.). The wrong thing to do is to try to add a few extra sentences or to scramble a few words or bullet points trying to avoid duplicate content detection. If I can spot duplicate content in a minute with a search, Google has time to do more in-depth duplicate detection in its index.
Next up was the Dollar Stretcher. I’d actually heard of this site before (stretcher.com), and everything I checked off-page and on-page looked fine. The site owner said that Google was doing fine on this site, but Yahoo! didn’t seem to like it. Greg Boser managed to find a sitemap-type page that listed hundreds of articles, but in my opinion it only looked bad because the site has been live since 1996 and they had tons of original articles that they had written over the years. So how should a webmaster make a sitemap on their site when they have hundreds of articles? My advice would be to break the sitemap up on your pages. Instead of hundreds of links all on one page, you could organize your articles chronologically (each year could be a page), alphabetically, or by topic. Danny and Todd noticed a mismatch between uppercase url titles on the live pages and lowercase url titles according Yahoo!’s Site Explorer, and a few folks started to wonder if cloaking was going on. The site was definitely hitting a “this is a legit site” chord for me, and I didn’t think they were cloaking, so I checked with a quick wget and also told Googlebot to fetch the page. It all checked out–no cloaking going on to Google. I gently tried to suggest that it might be a Site Explorer issue, which a few people took as a diss. No diss was intended to Site Explorer; I think it’s a fine way to explore urls; I just don’t think stretcher.com was trying to pull any tricks with lowercasing their titles to search engines (not that cloaking to lowercase a title is something that it would help a site anyway).
Holy crawp this is taking forever to write. Let me kick it into high gear. The real estate site was functional (~100-ish pages about different projects + 10 about us/contact sort of pages) about Las Vegas real estate, but it was also pretty close to brochureware. There was nothing compelling or exciting about the site. I recommended looking for good ways to attract links: surveys, articles about the crazy construction levels in Vegas, contests–basically just looking at ways to create a little buzz, as opposed to standard corporate brochureware sites. Linkbait doesn’t have to be sneaky or cunning; great content can be linkbait as well, if you let people know about it.
The chiropractor site looked good. Danny Sullivan made some good points that they wanted to show up for a keyword phrase, but that phrase didn’t occur on the site’s home page. Think about what users will type (and what you want to rank for), and make sure to use those words on your page. The site owner was also using Comic Sans, which is a font that a few people hate. I recommended something more conservative for a medical story. Greg Boser mentioned to be aware of local medical associations and similar community organizations. I recommended local newspapers, and gave the example that when my Mom shows up with a prepared article for her small hometown newspaper about a charity event, they’re usually happy to run it or something close to it. Don’t neglect local resources when you’re trying to promote your site.
My favorite for the real estate licensing site is that in less that a minute, I was able to find 50+ other domains that this person had–everything from learning Spanish to military training. So I got to say “Let us be frank, you and I: how many sites do you have?” He paused for a while, then said “a handful.” After I ran through several of his sites, he agree that he had quite a few. My quick take is that if you’re running 50 or a 100 domains yourself, you’re fundamentally different than the chiropractor with his one site: with that many domains, each domain doesn’t always get as much loving attention, and that can really show. Ask yourself how many domains you have, and if it’s so many that lots of domains end up a bit cookie-cutter-like.
Several times during the session, it was readily apparent that someone had tried to do reciprocal links as a “quick hit” to increase their link popularity. When I saw that in the backlinks, I tried to communicate that 1) it was immediately obvious to me, and therefore our algorithms can do a pretty good job of spotting excessive reciprocal links, and 2) in the instances that I looked at, the reciprocal links weren’t doing any good. I urged folks to spend more time looking for ways to make a compelling site that attract viral buzz or word of mouth. Compelling sites that are well-marketed attract editorially chosen links, which tend to help a site more.
The computer peripheral site had a few issues, but it was a solid site. They had genuine links from e.g. Lexar listing them as a place to buy their memory cards. When you’re a well-known site like that, it’s worth trying to find even more manufacturers whose products you sell. Links from computer part makers would be pretty good links, for example. The peripheral site had urls that were like /i-Linksys-WRT54G-Wireless-G-54Mbps-Broadband-Router-4-Port-10100Mbps-Switch-54Mbps-80211G-Access-Point-519
, which looks kinda cruddy. Instead of using the first 14-15 words of the description, the panel recommended truncating the keywords in the url to ~4-5 words. The site also had session ID stuff like “sid=te8is439m75w6mp” that I recommended to drop if they could. The site also had product categories, but the urls were like “/s-subcat-NETWORK~.html”. Personally, I think having “/network/” and then having the networking products in that subdirectory is a little cleaner.
The HiFi store was fine, but this was another example where someone had 40+ other sites. Having lots of sites isn’t bad, but I’ve mentioned the risk that not all the sites get as much attention as they should. In this case, 1-2 of the sites were stuff like cheap-cheap-(something-related-to-telephone-calling).com. Rather than any real content, most of the pages were pay-per-click (PPC) parked pages, and when I checked the whois on them, they all had “whois privacy protection service” on them. That’s relatively unusual. Having lots of sites isn’t automatically bad, and having PPC sites isn’t automatically bad, and having whois privacy turned on isn’t automatically bad, but once you get several of these factors all together, you’re often talking about a very different type of webmaster than the fellow who just has a single site or so.
Closing out on a fun note, the day spa was done by someone who was definitely a novice. The site owner seemed to have trouble accessing all the pages on the site, so she had loaded a ton of content onto the main page. But it was a real site, and it still ranked well at Yahoo! and Google. The site owner said that she’d been trying to find a good SEO for ages, so Todd guilted the audience and said “Will someone volunteer to help out this nice person for free?” A whole mess of people raised their hand–good evidence that SEOs have big hearts and that this site owner picked the right conference to ask for help.
Okay, that’s a rundown of SEO feedback on some real-world sites, and this post is like a gajillion words long, so I’ll stop now and save more write-ups for later.
Monday, December 11, 2006
Google Gets Personalized
Google Gets Personalized
by Kim Roach
Have you ever become overwhelmed by the number of documents accessible via a search engine? If you're like most people, then you probably have. There are often millions of results and not every result is likely to be of equal importance to you.
In addition to that, there is also ambiguity of language. Words often have multiple meanings and people can have different interpretations of the same word. How does a search engine know the difference? Well, at this point, they don't.
They certainly can't read your mind so the only other alternative is to track your online activities in order to custom tailor your search results based on your recorded preferences.
Google is one of the first major search engines to test this new technology. They have released a total of 15 new patent applications this month in relation to this very endeavor.
Actually, I'm not too surprised that Google is taking a closer look at personalization. Google has already begun testing many of these new search features in Google's personalized search http://www.google.com/psearch, which is currently in beta.
Traditional algorithmic search engines have reached their peak. Personalized search is a natural and necessary progression for Google and other search engines as well. Some alternative search engines have already taken the lead in this endeavor. Eurekster http://www.eurekster.comis one of the main ones that comes to mind, using a searchers history to bring them more relevant results.
Here is an abstract from one of the Google patents entitled, Systems and methods for analyzing a user's web history http://tinyurl.com/ycdhxl: A user's prior searching and browsing activities are recorded for subsequent use. A user may examine the user's prior searching and browsing activities in a number of different ways, including indications of the user's prior activities related to advertisements.
A set of search results may be modified in accordance with the user's historical activities. The user's activities may be examined to identify a set of preferred locations. The user's set of activities may be shared with one or more other users. The set of preferred locations presented to the user may be enhanced to include the preferred locations of one or more other users.
A user's browsing activities may be monitored from one or more different client devices or client application. A user's browsing volume may be graphically displayed.
Now, let's talk about all of that in English. Over time, we develop a history of search queries, selected results that were clicked on, advertisements that were clicked on, and a multitude of other browsing activities. Each of these actions reflect our preferences and interests. Other examples of user activity Google may begin tracking include instant messaging, word processing, participation in chat rooms, and internet phone calls.
Talk about an invasion of privacy. Unfortunately, we don't have enough time to get into that issue.
Within the proposed system, users are able to access their past searching and/or browsing activities to enhance their experience. Each of their online activities gives clues to what they might ultimately be looking for or related areas of interests.
In addition, users can also modify their profile information to better represent their interests. For example, a user may delete a search query from his/her history or he/she could also provide updated information as to new areas of interest.
One of the most interesting aspects of the patent filings involves the re-ranking of search results according to the user's preferences.
After a query is made and the results are received, they are then adjusted based upon information from the user's history. The order of the search results can be adjusted in accordance with a history score and/or any user modified result score. Search results can also be ordered based upon the combined search result score and the history score to come up with optimal results.
A searcher may also be shown an indication of previously visited pages among the SERPs, including information such as the date and time a page was previously visited and the number of times that the user has visited the site within a certain period of time.
A certain number of the most highly ranked results that the user has previously visited may be displayed in a region above the search results for easy access (kind of like memorized favorites).
They could also be displayed in another section of the page, or even in a separate window.These previously visited pages may be ordered based upon a number of different ranking criteria, including the history score, pagerank, time of last access, number of accesses, etc.
A user's browsing activities may also play a part in the ranking of search results. For example, if a website was previously visited by the user, it could have its score boosted based upon the number of times the user has visited that particular website. Google may also track how long a visitor stays at any given website. A site that is bookmarked and visited frequently will almost always rank higher.
On the other hand, search results that were previously presented to searchers but not clicked through could be lowered in the results.
What does this mean for you as a webmaster and SEO? It means that your focus should be on quality. In creating your website, you must emphasize visitor optimization and content optimization over search engine optimization.
The visitor always comes first and you must create a valuable experience for them. Allow them to quickly and easily bookmark your website. Give them a reason to hang out for a while, whether it be a forum, lots of great content, or fun quizzes.
The future of SEO is about creating quality, authority sites.
About This AuthorKim Roach is a staff writer and editor for the SiteProNews & SEO-Newsnewsletters. You can also find additional tips and news on webmaster and SEO topics by Kim at the SiteProNews blog. Kim's email is: kim@seo-news.comThis article may be freely distributed without modification and provided that the copyright notice and author information remain intact.
by Kim Roach
Have you ever become overwhelmed by the number of documents accessible via a search engine? If you're like most people, then you probably have. There are often millions of results and not every result is likely to be of equal importance to you.
In addition to that, there is also ambiguity of language. Words often have multiple meanings and people can have different interpretations of the same word. How does a search engine know the difference? Well, at this point, they don't.
They certainly can't read your mind so the only other alternative is to track your online activities in order to custom tailor your search results based on your recorded preferences.
Google is one of the first major search engines to test this new technology. They have released a total of 15 new patent applications this month in relation to this very endeavor.
Actually, I'm not too surprised that Google is taking a closer look at personalization. Google has already begun testing many of these new search features in Google's personalized search http://www.google.com/psearch, which is currently in beta.
Traditional algorithmic search engines have reached their peak. Personalized search is a natural and necessary progression for Google and other search engines as well. Some alternative search engines have already taken the lead in this endeavor. Eurekster http://www.eurekster.comis one of the main ones that comes to mind, using a searchers history to bring them more relevant results.
Here is an abstract from one of the Google patents entitled, Systems and methods for analyzing a user's web history http://tinyurl.com/ycdhxl: A user's prior searching and browsing activities are recorded for subsequent use. A user may examine the user's prior searching and browsing activities in a number of different ways, including indications of the user's prior activities related to advertisements.
A set of search results may be modified in accordance with the user's historical activities. The user's activities may be examined to identify a set of preferred locations. The user's set of activities may be shared with one or more other users. The set of preferred locations presented to the user may be enhanced to include the preferred locations of one or more other users.
A user's browsing activities may be monitored from one or more different client devices or client application. A user's browsing volume may be graphically displayed.
Now, let's talk about all of that in English. Over time, we develop a history of search queries, selected results that were clicked on, advertisements that were clicked on, and a multitude of other browsing activities. Each of these actions reflect our preferences and interests. Other examples of user activity Google may begin tracking include instant messaging, word processing, participation in chat rooms, and internet phone calls.
Talk about an invasion of privacy. Unfortunately, we don't have enough time to get into that issue.
Within the proposed system, users are able to access their past searching and/or browsing activities to enhance their experience. Each of their online activities gives clues to what they might ultimately be looking for or related areas of interests.
In addition, users can also modify their profile information to better represent their interests. For example, a user may delete a search query from his/her history or he/she could also provide updated information as to new areas of interest.
One of the most interesting aspects of the patent filings involves the re-ranking of search results according to the user's preferences.
After a query is made and the results are received, they are then adjusted based upon information from the user's history. The order of the search results can be adjusted in accordance with a history score and/or any user modified result score. Search results can also be ordered based upon the combined search result score and the history score to come up with optimal results.
A searcher may also be shown an indication of previously visited pages among the SERPs, including information such as the date and time a page was previously visited and the number of times that the user has visited the site within a certain period of time.
A certain number of the most highly ranked results that the user has previously visited may be displayed in a region above the search results for easy access (kind of like memorized favorites).
They could also be displayed in another section of the page, or even in a separate window.These previously visited pages may be ordered based upon a number of different ranking criteria, including the history score, pagerank, time of last access, number of accesses, etc.
A user's browsing activities may also play a part in the ranking of search results. For example, if a website was previously visited by the user, it could have its score boosted based upon the number of times the user has visited that particular website. Google may also track how long a visitor stays at any given website. A site that is bookmarked and visited frequently will almost always rank higher.
On the other hand, search results that were previously presented to searchers but not clicked through could be lowered in the results.
What does this mean for you as a webmaster and SEO? It means that your focus should be on quality. In creating your website, you must emphasize visitor optimization and content optimization over search engine optimization.
The visitor always comes first and you must create a valuable experience for them. Allow them to quickly and easily bookmark your website. Give them a reason to hang out for a while, whether it be a forum, lots of great content, or fun quizzes.
The future of SEO is about creating quality, authority sites.
About This AuthorKim Roach is a staff writer and editor for the SiteProNews & SEO-Newsnewsletters. You can also find additional tips and news on webmaster and SEO topics by Kim at the SiteProNews blog. Kim's email is: kim@seo-news.comThis article may be freely distributed without modification and provided that the copyright notice and author information remain intact.
Tuesday, October 10, 2006
More info on PageRank
Every few months we update the PageRank data that we show in the toolbar, and every few months I see a few repeated questions, so let me take a pass at some of them. Note: I wrote this kinda quickly, so I think this is pretty good, but if I spot something incorrect later, I’ll change it.
Philipp Lenssen asks: “Matt, I often wonder, how is the PageRank value stored internally, is it a floating-point number as many people suggest or is it just the integer value itself due to the heavy recursive PR computations?”
It’s more accurate to think of it as a floating-point number. Certainly our internal PageRank computations have many more degrees of resolution than the 0-10 values shown in the toolbar.
viggen says: “Do i need to know that? What does it tell me when i know it? Why would i care?
Meaning, what purpose has the Pagerank for the mom and pop site out there?”
viggen, I think that’s a perfectly healthy attitude. If you don’t care about PageRank and your site is doing well, that’s fine by me.
Andrew Hunter asks: “Will the data centers using the slightly older infrastructure be updated in due course, or will my PR be split by data center for the next couple of months?”
The latter. I think most data centers are running the newer infrastructure for things like info:, related:, link: and PageRank, and I believe every data center that has that newer infrastructure has the recent snapshot of PageRank now. I wouldn’t be surprised if it took at least 1-2 months for the other data center IPs to get the newer infrastructure in some way. (Yes, this is smaller, different infrastructure than the stuff that made site: queries have more accurate results estimates.)
Lots of folks ask questions like: “Is this PageRank from day X or day Y? And it looks like backlinks are from day Z?”
Really, I wouldn’t worry about it–I’m not even sure myself. At some point we take our internal PageRanks, put them on a 0-10 scale, and export them so that they’re visible to Google Toolbar users. If you’re splitting hairs about the exact date that backlinks were taken from, you’re probably suffering from “B.O.” (backlink obsession) and should stop and go do something else for a bit until the backlink obsession passes. I highly recommend keyword analysis, looking at server logs to figure out new content to add, thinking of new hooks to make your site attract more word-of-mouth buzz, pondering how to improve conversion once visitors land on your site, etc.
I’ll do a follow-up. Supplemental Challenged said: “The fact that Google can only create a PR update that is a full quarter behind the times is awfully troubling.”
I believe that I’ve said before that PageRank is computed continuously; there are machines that take inputs to the PageRank algorithm at Google and compute the resulting PageRanks. So at any given time, a url in Google’s system has up-to-date PageRank as a result of running the computation with the inputs to the algorithm. From time-to-time, that internal PageRank value is exported so that it’s visible to Google Toolbar users (see the question below for more details on the timing).
Matt Crouch asks: “Actually, I am just curious why you are bothering telling us about a new PR update…. is this the first time you ever did?”
Well asked, Matt Crouch; I’m not sure if I’ve given the official word on a PageRank export before. It’s not a big event here at Google. Frankly, I didn’t even know we’d done our 3-4 month-ish push of this data. When I saw people talking about it online, I went to check and see whether it was a real push or not. In the past few months, people have noticed when an engineer grabs an obscure data center and tinkers around with things like backlinks or info: queries (e.g. when “Update Pluto” got downgraded because it was just an engineer tinkering at one data center). So I figured I’d let people know that this was a real PageRank export and not just one person doing something.
New Jersey SEO asked: “Will this PR update affect SERPs? Are we going to have also a SERP data refresh / update?”
Great question. By the time you see newer PageRanks in the toolbar, those values have already been incorporated in how we score/rank our search results. So while you may be happy to see that the Google Toolbar shows a little more PageRank for a given page, it’s not as if that causes a change in search results at that point. So you won’t see any search engine result page (SERP) changes as a result of this PageRank export–those changes have been gradually baking in since the last PageRank export.
Philipp Lenssen asks: “Matt, I often wonder, how is the PageRank value stored internally, is it a floating-point number as many people suggest or is it just the integer value itself due to the heavy recursive PR computations?”
It’s more accurate to think of it as a floating-point number. Certainly our internal PageRank computations have many more degrees of resolution than the 0-10 values shown in the toolbar.
viggen says: “Do i need to know that? What does it tell me when i know it? Why would i care?
Meaning, what purpose has the Pagerank for the mom and pop site out there?”
viggen, I think that’s a perfectly healthy attitude. If you don’t care about PageRank and your site is doing well, that’s fine by me.
Andrew Hunter asks: “Will the data centers using the slightly older infrastructure be updated in due course, or will my PR be split by data center for the next couple of months?”
The latter. I think most data centers are running the newer infrastructure for things like info:, related:, link: and PageRank, and I believe every data center that has that newer infrastructure has the recent snapshot of PageRank now. I wouldn’t be surprised if it took at least 1-2 months for the other data center IPs to get the newer infrastructure in some way. (Yes, this is smaller, different infrastructure than the stuff that made site: queries have more accurate results estimates.)
Lots of folks ask questions like: “Is this PageRank from day X or day Y? And it looks like backlinks are from day Z?”
Really, I wouldn’t worry about it–I’m not even sure myself. At some point we take our internal PageRanks, put them on a 0-10 scale, and export them so that they’re visible to Google Toolbar users. If you’re splitting hairs about the exact date that backlinks were taken from, you’re probably suffering from “B.O.” (backlink obsession) and should stop and go do something else for a bit until the backlink obsession passes. I highly recommend keyword analysis, looking at server logs to figure out new content to add, thinking of new hooks to make your site attract more word-of-mouth buzz, pondering how to improve conversion once visitors land on your site, etc.
I’ll do a follow-up. Supplemental Challenged said: “The fact that Google can only create a PR update that is a full quarter behind the times is awfully troubling.”
I believe that I’ve said before that PageRank is computed continuously; there are machines that take inputs to the PageRank algorithm at Google and compute the resulting PageRanks. So at any given time, a url in Google’s system has up-to-date PageRank as a result of running the computation with the inputs to the algorithm. From time-to-time, that internal PageRank value is exported so that it’s visible to Google Toolbar users (see the question below for more details on the timing).
Matt Crouch asks: “Actually, I am just curious why you are bothering telling us about a new PR update…. is this the first time you ever did?”
Well asked, Matt Crouch; I’m not sure if I’ve given the official word on a PageRank export before. It’s not a big event here at Google. Frankly, I didn’t even know we’d done our 3-4 month-ish push of this data. When I saw people talking about it online, I went to check and see whether it was a real push or not. In the past few months, people have noticed when an engineer grabs an obscure data center and tinkers around with things like backlinks or info: queries (e.g. when “Update Pluto” got downgraded because it was just an engineer tinkering at one data center). So I figured I’d let people know that this was a real PageRank export and not just one person doing something.
New Jersey SEO asked: “Will this PR update affect SERPs? Are we going to have also a SERP data refresh / update?”
Great question. By the time you see newer PageRanks in the toolbar, those values have already been incorporated in how we score/rank our search results. So while you may be happy to see that the Google Toolbar shows a little more PageRank for a given page, it’s not as if that causes a change in search results at that point. So you won’t see any search engine result page (SERP) changes as a result of this PageRank export–those changes have been gradually baking in since the last PageRank export.
Tuesday, September 19, 2006
Google's new Sitelinks and your web site
Google recently started to include a set of links below some results to pages within the site. These new additional links are called Sitelinks.
It seems that Google displays Sitelinks if a web site is an authority site for the search term.
What are Google Sitelinks?
Google explains the new links on its webmaster pages:
How do you compile the list of links shown below some search results?
The links shown below some sites in our search results, called Sitelinks, are meant to help users navigate your site. Our systems analyze the link structure of your site to find shortcuts that will save users time and allow them to quickly find the information they're looking for.
We only show Sitelinks for results when we think they'll be useful to the user. If the structure of your site doesn't allow our algorithms to find good Sitelinks, or we don't think that the Sitelinks for your site are relevant for the user's query, we won't show them.
At the moment, Sitelinks are completely automated. We're always working to improve our Sitelinks algorithms, and we may incorporate webmaster input in the future.
How does Google calculate Sitelinks?
Google claims that the Sitelinks are created automatically. If Google uses an algorithm to calculate Sitelinks, there must be a way to influence that algorithm.
There are several theories on how Sitelinks are calculated:
1. Google might track the number of clicks for different results. If a web site gets a lot of traffic for a special keyword then the web site will get Sitelinks on Google's result page.For example, if you use a special trademark term on your web pages that cannot be found on other web sites then many people will click on your web site in Google's results when they search for that search term. It's likely that your web site will get Sitelinks for such a search term.
2. The link architecture of a web site might help. Links at the top of the HTML source of a web site seem to have a better chance to be included as Sitelinks.
3. Google might use the Google toolbar to determine Sitelinks. The more often a page is bookmarked the more likely it is that these pages will be used as Sitelinks. Google's toolbar can collect a lot of information about a web site.
At the moment, it's hard to tell how Google calculates the new Sitelinks. It's probably a combination of click data, toolbar data and other factors. If you see Sitelinks for your web site, then Google has probably classified your web site as an authority site for the search term.
How does this affect your web site?
It seems that Sitelinks are only used for trademark searches or searches that are similar to trademark queries.
Most search engine result pages on Google don't show these additional links.
That means that it's better to invest some time in getting listed in Google's regular result pages than trying to get listed with additional Sitelinks.
It seems that Google displays Sitelinks if a web site is an authority site for the search term.
What are Google Sitelinks?
Google explains the new links on its webmaster pages:
How do you compile the list of links shown below some search results?
The links shown below some sites in our search results, called Sitelinks, are meant to help users navigate your site. Our systems analyze the link structure of your site to find shortcuts that will save users time and allow them to quickly find the information they're looking for.
We only show Sitelinks for results when we think they'll be useful to the user. If the structure of your site doesn't allow our algorithms to find good Sitelinks, or we don't think that the Sitelinks for your site are relevant for the user's query, we won't show them.
At the moment, Sitelinks are completely automated. We're always working to improve our Sitelinks algorithms, and we may incorporate webmaster input in the future.
How does Google calculate Sitelinks?
Google claims that the Sitelinks are created automatically. If Google uses an algorithm to calculate Sitelinks, there must be a way to influence that algorithm.
There are several theories on how Sitelinks are calculated:
1. Google might track the number of clicks for different results. If a web site gets a lot of traffic for a special keyword then the web site will get Sitelinks on Google's result page.For example, if you use a special trademark term on your web pages that cannot be found on other web sites then many people will click on your web site in Google's results when they search for that search term. It's likely that your web site will get Sitelinks for such a search term.
2. The link architecture of a web site might help. Links at the top of the HTML source of a web site seem to have a better chance to be included as Sitelinks.
3. Google might use the Google toolbar to determine Sitelinks. The more often a page is bookmarked the more likely it is that these pages will be used as Sitelinks. Google's toolbar can collect a lot of information about a web site.
At the moment, it's hard to tell how Google calculates the new Sitelinks. It's probably a combination of click data, toolbar data and other factors. If you see Sitelinks for your web site, then Google has probably classified your web site as an authority site for the search term.
How does this affect your web site?
It seems that Sitelinks are only used for trademark searches or searches that are similar to trademark queries.
Most search engine result pages on Google don't show these additional links.
That means that it's better to invest some time in getting listed in Google's regular result pages than trying to get listed with additional Sitelinks.
Monday, September 11, 2006
The Orion Algorithm And Your SEO Efforts
By: Mark Nenadic
Every so often there is a new development that is so enormous that it changes the way the entire SEO-using world works with their websites for optimization and proper promotional structuring.
Most recently was the purchasing of the rights to the Orion Algorithm by Google. Equally important is that Yahoo! and MSN have both taken an interest in the Orion Algorithm and vied for its ownership.
The Orion Algorithm " for those of you who arent working for a search engine " is something that has actually been kept quite secret. Its specifics are not known, but what is understood is that it is a new technology for the performance of search engines. It allows search results to be immediately displayed as expanded text extracts so that users will know the relevant information without having to actually check the site to make sure that it is what they are looking for. The option to visit the website is, however, still quite available if the user chooses to opt for it.
To web designers, search engine optimizers, and other website owners, it means that there will likely be another shift in the way that websites are ranked and indexed. Furthermore, the traffic to the website will be much more specific to that sites target market, as fewer people will land there only to find that it is not what they are looking for.
For users in general, this will mean that the results that are displayed using Google searches will be much more similar to those found at Ask.com. It will allow users to judge the sites content compared to what theyre looking for without having to click the link. It will make searching much simpler and more practical for users who will be able to review everything all in one place. Then, when they come upon the site or sites that interest them, they may still click the link and find out what the site is all about in more depth.
This means that the Orion Algorithm is essentially an entirely new way of evaluating websites with regards to the search terms that are used for them. Instead of ranking the website based on the search phrase being used by the user, the Orion Algorithm may also dig a bit deeper into the phrase, searching also for related phrases. This concept, while not entirely new for directories, is the first of its kind for the standard search engines that are typically used on the internet. This will mean that search engine optimizers will need to change their overall strategy so that they will now appeal to search engines in different ways.
Among the techniques that may be utilized in searching with other relevant terms with the Orion Algorithm are the following. Their relevancy and weight has not been determined, as the Orion Algorithm is being held in the deepest secrecy. However, knowing what we do about Orion, it is logical to believe the following:
1 - Directories are the least likely to be considered using relevant phrases. Though they may be utilized for supplementary keyword sources, they will not likely be considered as results in themselves. The drawback presented by this approach is that there will therefore not be as many cross-referenced popular keywords as there are currently due to the results brought up by directories with a search engine query.
2 - Thesaurus are relatively unlikely to be used for discovering related phrases since the technique rarely works for related keyword phrases that are used with searches. It may be possible for single word searches, but as soon as multiple words are used, or even when acronyms are employed, it is much more difficult to find proper terms using thesauruses.
3 - Search behavior is also unlikely to be used in order to document relevancy for future searches. The concept is sound, as it would allow search behavior patterns to be collected and then predicted. However, this would not allow for decent results until the search engines have had enough time to compile adequate results and then assess the behaviors that have been recorded.
We may never know precisely what goes into the Orion Algorithm, but search engine optimizers " as always " will continue testing new results for creating sites that are most likely to achieve superior search engine ranking results.
Also see:
Google and the Orion Algorithm
Google Inc. has acquired "Orion" search engine technology from an Australian university that last year described the product as potentially revolutionary.
Every so often there is a new development that is so enormous that it changes the way the entire SEO-using world works with their websites for optimization and proper promotional structuring.
Most recently was the purchasing of the rights to the Orion Algorithm by Google. Equally important is that Yahoo! and MSN have both taken an interest in the Orion Algorithm and vied for its ownership.
The Orion Algorithm " for those of you who arent working for a search engine " is something that has actually been kept quite secret. Its specifics are not known, but what is understood is that it is a new technology for the performance of search engines. It allows search results to be immediately displayed as expanded text extracts so that users will know the relevant information without having to actually check the site to make sure that it is what they are looking for. The option to visit the website is, however, still quite available if the user chooses to opt for it.
To web designers, search engine optimizers, and other website owners, it means that there will likely be another shift in the way that websites are ranked and indexed. Furthermore, the traffic to the website will be much more specific to that sites target market, as fewer people will land there only to find that it is not what they are looking for.
For users in general, this will mean that the results that are displayed using Google searches will be much more similar to those found at Ask.com. It will allow users to judge the sites content compared to what theyre looking for without having to click the link. It will make searching much simpler and more practical for users who will be able to review everything all in one place. Then, when they come upon the site or sites that interest them, they may still click the link and find out what the site is all about in more depth.
This means that the Orion Algorithm is essentially an entirely new way of evaluating websites with regards to the search terms that are used for them. Instead of ranking the website based on the search phrase being used by the user, the Orion Algorithm may also dig a bit deeper into the phrase, searching also for related phrases. This concept, while not entirely new for directories, is the first of its kind for the standard search engines that are typically used on the internet. This will mean that search engine optimizers will need to change their overall strategy so that they will now appeal to search engines in different ways.
Among the techniques that may be utilized in searching with other relevant terms with the Orion Algorithm are the following. Their relevancy and weight has not been determined, as the Orion Algorithm is being held in the deepest secrecy. However, knowing what we do about Orion, it is logical to believe the following:
1 - Directories are the least likely to be considered using relevant phrases. Though they may be utilized for supplementary keyword sources, they will not likely be considered as results in themselves. The drawback presented by this approach is that there will therefore not be as many cross-referenced popular keywords as there are currently due to the results brought up by directories with a search engine query.
2 - Thesaurus are relatively unlikely to be used for discovering related phrases since the technique rarely works for related keyword phrases that are used with searches. It may be possible for single word searches, but as soon as multiple words are used, or even when acronyms are employed, it is much more difficult to find proper terms using thesauruses.
3 - Search behavior is also unlikely to be used in order to document relevancy for future searches. The concept is sound, as it would allow search behavior patterns to be collected and then predicted. However, this would not allow for decent results until the search engines have had enough time to compile adequate results and then assess the behaviors that have been recorded.
We may never know precisely what goes into the Orion Algorithm, but search engine optimizers " as always " will continue testing new results for creating sites that are most likely to achieve superior search engine ranking results.
Also see:
Google and the Orion Algorithm
Google Inc. has acquired "Orion" search engine technology from an Australian university that last year described the product as potentially revolutionary.
Tuesday, August 01, 2006
Optimize for Search Engines or Users?
Video and SEO FAQ's from MATT CUTTS the Google GUY!
Session 1: Including qualities of a good site.
Session 2: Including some SEO Myths.
Session 3: Should you Optimize for Search Engines or for Users?
Session 1: Including qualities of a good site.
Session 2: Including some SEO Myths.
Session 3: Should you Optimize for Search Engines or for Users?
Monday, July 24, 2006
The Google Toolbar PageRank Demystified
Did you know that I don’t know what I am doing? It’s true. At least that’s how I feel sometimes when dealing with the SEO/SEM aspects of my job.
Many of my areas of operation are so beautifully stable and predictable, at least within reason. Working with programmers, we have a plan and a language to follow to achieve our goals. Life in the accounting department is fairly stable in its approaches. Administrative, Customer relations, human resource development? They all have some form of measurable reality.
Search engine optimization? Not a chance. We’re not even let into the kitchen to see what’s in the fridge, never mind given the recipe to cook a feast for our clients. It is a truly interesting and challenging aspect of Internet business development. It is tantamount to working in the dark or having business plans plucked from the pages of the grocery store rag. Heck, maybe Aliens can tell me the truth about the algorithms. Maybe even Macdonald’s ‘secret’ sauce while they’re at it.
Beware of the Great Beasts of Google!
This brings me to the greatest mythological creature to roam the Google landscape since ‘the sandbox’; The Google Toolbar Page Rank (TBPR) system. While the jury may still be out on the ‘sandbox’, I am here to slay the beast that is the TBPR, right here, right now. Forever let it rest in peace where it truly belongs, in Google purgatory. I am not saying it is without its relative value, it’s mere existence quantifies that. It just doesn’t have a ‘measurable’ value that warrants earmarking any serious marketing dollars. It is being overvalued in today’s SEO landscape. Don’t spend time and money trying to get a higher Page Rank. Just love it for what it is.
I have not taken this journey lightly. As a consequence of the ‘mystery’ surrounding the algorithms and the SEO community, I knew there would be those to lash out in a vain attempt to hold onto the LGB (little green bar) that is so much a part of their culture. He is a destructive beast though. Eating up great swaths of forum boards, causing countless hours of ‘webmaster worry’ and even deluding the minds of its followers. I am truly sorry, but it must end. This creature must die. We must move on to ‘greener’ pastures of content relevance, semantic indexing, organic link building and the other wonders that we have from the great Search Engine Gods.
What is this Page Rank Phenomenon?
PageRank is, in essence, a rough system for estimating the value of a given link based on the links that point to the host page. Since PageRank's inception in the late '90s, more subtle and sophisticated link analysis systems have taken the place of PageRank.
Thus, in the modern era of SEO, the PageRank measurement in Google's toolbar, directory, or through sites that query the service is of limited value. Pages with PR8 can be found ranked 20-30 positions below pages with a PR3 or PR4. Additionally, the toolbar numbers are updated only every 3-6 months, making the values even less useful. Rather than focusing on PageRank, it's important to think holistically about a link's worth. Have an organic approach to things.
What doesn’t seem to be commonly known is its ‘true’ and ‘measurable’ value in the marketing landscape. I have spent far too many hours of mind numbing technical document and conventional wisdom research that has lead me to my eventual perspective on the whole Page Rank and it’s ‘relevance’ (a little LSA humor there) as far as it relates to being part of a meaningful online marketing campaign.
The Value of Google’s Page Rank System
At the core of my interest is ‘value’. What is the value of the LGB? Is there one? If so, then how can it be defined and measured for ROI. I don’t look at SEO as a hobby nor a passing interest. It’s about business. It is a service that is part of a larger scheme of Internet business development. As such I have to quantify my action and investments (of time and money) spent on my activities, which is none too easy in the SEO world.
I have for too long watched and listened to a variety of hubbub about Page Rank (PR) and the Google toolbar phenomenon. I looked into, found little that warranted further research investment and we moved onto other aspects of SEM/SEO. Well, doesn’t that little beast just keeps growing, as does the myth. People’s beliefs and ideas surrounding the TBPR system it is truly incredible.
Listen to the Masters of Yore
I have had it argued, in all seriousness, that the TBPR had a value as consumers would consult it for ‘authority’ prior to making a purchase. Oh come on!
As penned by SE Guru Mike Grehan,
“Can you imagine some surfer finding the digital camera of his dreams at a knock-down bargain price but refusing to buy it because the page it's on only has a PR of one? I don't think so.”
Grehan did an interview in 2003 with Google engineer, Daniel Dulitz. When asked about data accuracy in the toolbar meter. He told Mike that there are two elements: accuracy and precision. The toolbar is accurate but not very precise. He added, "We have a lot more precision available to us than we represent in a 10-step scale."
When asked about the obsession to ‘the little green bar’ by the SEO community and webmasters, Dulitz said,
For search engine marketing, search engine optimization purposes, yeah, I'd say that there's too much emphasis placed on what that PR number actually is.... So, if people are trying to look at what we're doing and their idea is based on that single thing from 1 to 10, then... well, they're not going to be effective in figuring out what we're doing at all.”
In an interview with Lee Odden at the WebmasterWorld Pubcon in the spring of 2006;
Given the attention that people have given to PageRank, which is in Google’s toolbar, you can see how I’d feel about using toolbar data. I’m not going to say whether Google uses a particular signal in our ranking; I just wanted to communicate some of the potential problems in using things like toolbar data.”
Another chat between Matt and Lee produced “Google does not use toolbar data for rankings. He mentioned that it certainly didn't help that in the "Meet the Crawlers" session at SES NYC, the MSN rep suggested that MSN "might" be using user/toolbar info. That suggests the other search engines do as well. Matt also said that user data would be too easy to spam to use for rankings.”
Toolbar Page Rank is Dead! Long Live Targeted Traffic!
Is not the end-game of Internet marketing and SEO, getting more targeted traffic? From which, we hope to illicit the best possible conversion rates? Honestly, in my SEM/SEO background and training, Toolbar PR has not more than a passing metric for general consumption for quite some time. Those selling text link advertising would have you believe it is the all powerful measuring tool. Strange, I have seen PR0 Sites with better SERPs and traffic than PR6. Isn’t my advertising about the distribution channel?
Do I want my advertising on the site with a pretty green bar that read 6, or on the site that actually gets the traffic I am targeting? For some reason, SEO folks have a skewed marketing perspective and like things the other way around.
Just like so many websites disappearing into the Google sandbox, let this menace of Google PR terrorize SEO’s and Webmasters alike no longer. Let us rejoice and move onto new and wonderful lands with promises of getting traffic. Wonderful, life giving, targeted traffic. That’s truly what matters to the website. It’s the food that gives it life. I shall see you on the other side. Please leave this place or Page Rank hell now, before it’s too late.
Make your own conclusions;
Article Resources; Grehan ClickZ article; http://clickz.com/experts/search/results/article.php/3522286 Grehan interview ; http://www.e-marketing-news.co.uk/december_2003.html Lee and Matt II; http://www.toprankblog.com/2006/04/matt-cutts-on-toolbar-data/ Lee and Matt I; http://www.searchnewz.com/searchnewz-12-20060419YPNPartyBostonPubcon.html
Many of my areas of operation are so beautifully stable and predictable, at least within reason. Working with programmers, we have a plan and a language to follow to achieve our goals. Life in the accounting department is fairly stable in its approaches. Administrative, Customer relations, human resource development? They all have some form of measurable reality.
Search engine optimization? Not a chance. We’re not even let into the kitchen to see what’s in the fridge, never mind given the recipe to cook a feast for our clients. It is a truly interesting and challenging aspect of Internet business development. It is tantamount to working in the dark or having business plans plucked from the pages of the grocery store rag. Heck, maybe Aliens can tell me the truth about the algorithms. Maybe even Macdonald’s ‘secret’ sauce while they’re at it.
Beware of the Great Beasts of Google!
This brings me to the greatest mythological creature to roam the Google landscape since ‘the sandbox’; The Google Toolbar Page Rank (TBPR) system. While the jury may still be out on the ‘sandbox’, I am here to slay the beast that is the TBPR, right here, right now. Forever let it rest in peace where it truly belongs, in Google purgatory. I am not saying it is without its relative value, it’s mere existence quantifies that. It just doesn’t have a ‘measurable’ value that warrants earmarking any serious marketing dollars. It is being overvalued in today’s SEO landscape. Don’t spend time and money trying to get a higher Page Rank. Just love it for what it is.
I have not taken this journey lightly. As a consequence of the ‘mystery’ surrounding the algorithms and the SEO community, I knew there would be those to lash out in a vain attempt to hold onto the LGB (little green bar) that is so much a part of their culture. He is a destructive beast though. Eating up great swaths of forum boards, causing countless hours of ‘webmaster worry’ and even deluding the minds of its followers. I am truly sorry, but it must end. This creature must die. We must move on to ‘greener’ pastures of content relevance, semantic indexing, organic link building and the other wonders that we have from the great Search Engine Gods.
What is this Page Rank Phenomenon?
PageRank is, in essence, a rough system for estimating the value of a given link based on the links that point to the host page. Since PageRank's inception in the late '90s, more subtle and sophisticated link analysis systems have taken the place of PageRank.
Thus, in the modern era of SEO, the PageRank measurement in Google's toolbar, directory, or through sites that query the service is of limited value. Pages with PR8 can be found ranked 20-30 positions below pages with a PR3 or PR4. Additionally, the toolbar numbers are updated only every 3-6 months, making the values even less useful. Rather than focusing on PageRank, it's important to think holistically about a link's worth. Have an organic approach to things.
What doesn’t seem to be commonly known is its ‘true’ and ‘measurable’ value in the marketing landscape. I have spent far too many hours of mind numbing technical document and conventional wisdom research that has lead me to my eventual perspective on the whole Page Rank and it’s ‘relevance’ (a little LSA humor there) as far as it relates to being part of a meaningful online marketing campaign.
The Value of Google’s Page Rank System
At the core of my interest is ‘value’. What is the value of the LGB? Is there one? If so, then how can it be defined and measured for ROI. I don’t look at SEO as a hobby nor a passing interest. It’s about business. It is a service that is part of a larger scheme of Internet business development. As such I have to quantify my action and investments (of time and money) spent on my activities, which is none too easy in the SEO world.
I have for too long watched and listened to a variety of hubbub about Page Rank (PR) and the Google toolbar phenomenon. I looked into, found little that warranted further research investment and we moved onto other aspects of SEM/SEO. Well, doesn’t that little beast just keeps growing, as does the myth. People’s beliefs and ideas surrounding the TBPR system it is truly incredible.
Listen to the Masters of Yore
I have had it argued, in all seriousness, that the TBPR had a value as consumers would consult it for ‘authority’ prior to making a purchase. Oh come on!
As penned by SE Guru Mike Grehan,
“Can you imagine some surfer finding the digital camera of his dreams at a knock-down bargain price but refusing to buy it because the page it's on only has a PR of one? I don't think so.”
Grehan did an interview in 2003 with Google engineer, Daniel Dulitz. When asked about data accuracy in the toolbar meter. He told Mike that there are two elements: accuracy and precision. The toolbar is accurate but not very precise. He added, "We have a lot more precision available to us than we represent in a 10-step scale."
When asked about the obsession to ‘the little green bar’ by the SEO community and webmasters, Dulitz said,
For search engine marketing, search engine optimization purposes, yeah, I'd say that there's too much emphasis placed on what that PR number actually is.... So, if people are trying to look at what we're doing and their idea is based on that single thing from 1 to 10, then... well, they're not going to be effective in figuring out what we're doing at all.”
In an interview with Lee Odden at the WebmasterWorld Pubcon in the spring of 2006;
Given the attention that people have given to PageRank, which is in Google’s toolbar, you can see how I’d feel about using toolbar data. I’m not going to say whether Google uses a particular signal in our ranking; I just wanted to communicate some of the potential problems in using things like toolbar data.”
Another chat between Matt and Lee produced “Google does not use toolbar data for rankings. He mentioned that it certainly didn't help that in the "Meet the Crawlers" session at SES NYC, the MSN rep suggested that MSN "might" be using user/toolbar info. That suggests the other search engines do as well. Matt also said that user data would be too easy to spam to use for rankings.”
Toolbar Page Rank is Dead! Long Live Targeted Traffic!
Is not the end-game of Internet marketing and SEO, getting more targeted traffic? From which, we hope to illicit the best possible conversion rates? Honestly, in my SEM/SEO background and training, Toolbar PR has not more than a passing metric for general consumption for quite some time. Those selling text link advertising would have you believe it is the all powerful measuring tool. Strange, I have seen PR0 Sites with better SERPs and traffic than PR6. Isn’t my advertising about the distribution channel?
Do I want my advertising on the site with a pretty green bar that read 6, or on the site that actually gets the traffic I am targeting? For some reason, SEO folks have a skewed marketing perspective and like things the other way around.
Just like so many websites disappearing into the Google sandbox, let this menace of Google PR terrorize SEO’s and Webmasters alike no longer. Let us rejoice and move onto new and wonderful lands with promises of getting traffic. Wonderful, life giving, targeted traffic. That’s truly what matters to the website. It’s the food that gives it life. I shall see you on the other side. Please leave this place or Page Rank hell now, before it’s too late.
Make your own conclusions;
Article Resources; Grehan ClickZ article; http://clickz.com/experts/search/results/article.php/3522286 Grehan interview ; http://www.e-marketing-news.co.uk/december_2003.html Lee and Matt II; http://www.toprankblog.com/2006/04/matt-cutts-on-toolbar-data/ Lee and Matt I; http://www.searchnewz.com/searchnewz-12-20060419YPNPartyBostonPubcon.html
Tuesday, July 04, 2006
Do Search Engines Care About Valid HTML?
Like most web developers, I've heard a lot about the importance of valid html recently. I've read about how it makes it easier for people with disabilities to access your site, how it's more stable for browsers, and how it will make your site easier to be indexed by the search engines.
So when I set out to design my most recent site, I made sure that I validated each and every page of the site. But then I got to thinking – while it may make my site easier to index, does that mean that it will improve my search engine rankings? How many of the top sites have valid html?
To get a feel for how much value the search engines place on being html validated, I decided to do a little experiment. I started by downloading the handy Firefox HTML Validator Extension (http://users.skynet.be/mgueury/mozilla/) that shows in the corner of the browser whether or not the current page you are on is valid html. It shows a green check when the page is valid, an exclamation point when there are warnings, and a red x when there are serious errors.
I decided to use Yahoo! Buzz Index to determine the top 5 most searched terms for the day, which happened to be "World Cup 2006", "WWE", "FIFA", "Shakira", and "Paris Hilton". I then searched each term in the big three search engines (Google, Yahoo!, and MSN) and checked the top 10 results for each with the validator. That gave me 150 of the most important data points on the web for that day.
The results were particularly shocking to me – only 7 of the 150 resulting pages had valid html (4.7%). 97 of the 150 had warnings (64.7%) while 46 of the 150 received the red x (30.7%). The results were pretty much independent of search engine or term. Google had only 4 out of 50 results validate (8%), MSN had 3 of 50 (6%), and Yahoo! had none. The term with the most valid results was "Paris Hilton" which turned up 3 of the 7 valid pages. Now I realize that this isn't a completely exhaustive study, but it at least shows that valid html doesn't seem to be much of a factor for the top searches on the top search engines.
Even more surprising was that none of the three search engines home pages validated! How important is valid html if Google, Yahoo!, and MSN don't even practice it themselves? It should be noted, however, that MSN's results page was valid html. Yahoo's homepage had 154 warnings, MSN's had 65, and Google's had 22. Google's search results page not only didn't validate, it had 6 errors!
In perusing the web I also noticed that immensely popular sites like ESPN.com, IMDB, and MySpace don't validate. So what is one to conclude from all of this?
It's reasonable to conclude that at this time valid html isn't going to help you improve your search position. If it has any impact on results, it is minimal compared to other factors. The other reasons to use valid html are strong and I would still recommend all developers begin validating their sites; just don't expect that doing it will catapult you up the search rankings right now.
About the Author: Adam McFarland owns iPrioritize - to-do lists that can be edited at any time from any place in the world. Email, print, check from your mobile phone, subscribe via RSS, and share with others.
ALSO SEE:
Validation Isn't Everything
Like it or not, industry jargon often coughs up terms that become buzzwords. When this occurs—and it occurs across the board; web development is no exception—the terms can become diluted, even ambiguous...
So when I set out to design my most recent site, I made sure that I validated each and every page of the site. But then I got to thinking – while it may make my site easier to index, does that mean that it will improve my search engine rankings? How many of the top sites have valid html?
To get a feel for how much value the search engines place on being html validated, I decided to do a little experiment. I started by downloading the handy Firefox HTML Validator Extension (http://users.skynet.be/mgueury/mozilla/) that shows in the corner of the browser whether or not the current page you are on is valid html. It shows a green check when the page is valid, an exclamation point when there are warnings, and a red x when there are serious errors.
I decided to use Yahoo! Buzz Index to determine the top 5 most searched terms for the day, which happened to be "World Cup 2006", "WWE", "FIFA", "Shakira", and "Paris Hilton". I then searched each term in the big three search engines (Google, Yahoo!, and MSN) and checked the top 10 results for each with the validator. That gave me 150 of the most important data points on the web for that day.
The results were particularly shocking to me – only 7 of the 150 resulting pages had valid html (4.7%). 97 of the 150 had warnings (64.7%) while 46 of the 150 received the red x (30.7%). The results were pretty much independent of search engine or term. Google had only 4 out of 50 results validate (8%), MSN had 3 of 50 (6%), and Yahoo! had none. The term with the most valid results was "Paris Hilton" which turned up 3 of the 7 valid pages. Now I realize that this isn't a completely exhaustive study, but it at least shows that valid html doesn't seem to be much of a factor for the top searches on the top search engines.
Even more surprising was that none of the three search engines home pages validated! How important is valid html if Google, Yahoo!, and MSN don't even practice it themselves? It should be noted, however, that MSN's results page was valid html. Yahoo's homepage had 154 warnings, MSN's had 65, and Google's had 22. Google's search results page not only didn't validate, it had 6 errors!
In perusing the web I also noticed that immensely popular sites like ESPN.com, IMDB, and MySpace don't validate. So what is one to conclude from all of this?
It's reasonable to conclude that at this time valid html isn't going to help you improve your search position. If it has any impact on results, it is minimal compared to other factors. The other reasons to use valid html are strong and I would still recommend all developers begin validating their sites; just don't expect that doing it will catapult you up the search rankings right now.
About the Author: Adam McFarland owns iPrioritize - to-do lists that can be edited at any time from any place in the world. Email, print, check from your mobile phone, subscribe via RSS, and share with others.
ALSO SEE:
Validation Isn't Everything
Like it or not, industry jargon often coughs up terms that become buzzwords. When this occurs—and it occurs across the board; web development is no exception—the terms can become diluted, even ambiguous...
Wednesday, June 28, 2006
Google goes to court to defend its ranking methods
By Juan Carlos Perez, IDG News Service
Google will try to convince a judge on Friday to dismiss a lawsuit that challenges the heart of the company’s business: its methods for indexing and ranking Web pages.
In March, Google was sued by KinderStart.com , which alleges it suffered crippling financial harm after its Web site got dropped from the search engine’s index.
The case reflects the enormous impact of search engines on the business world at large. It has become crucial for many businesses to rank well in search engine results. An entire industry has sprouted to serve this “search engine optimization” need.
As the world’s most popular search engine, Google wields the strongest influence. Having a Web site that ranks low or disappears altogether from the Google index can have devastating effects for a company. This is what KinderStart.com alleges happened to it.
“It’s a very important case for many reasons. Everyone uses search engines, so the question is: Are you seeing true and faithful results?” said Gregory Yu, KinderStart.com’s attorney.
“Google shouldn’t have completely free range to be able to remove sites or hit them with a zero PageRank,” he added, referring to the patented technology at the heart of Google’s algorithmic ranking.
KinderStart.com is charging Google, among other things, with violating its right to free speech; illegally using a monopoly position to harm competitors; engaging in unfair practices and competition; committing defamation and libel; and violating the Federal Communications Act.
The Web publisher seeks a class action certification for the lawsuit, damages and injunctive relief, among other things.
In motions filed in May, Google argues that Judge Jeremy Fogel, of the U.S. District Court for the Northern District of California, San Jose Division, should dismiss the lawsuit, saying that the case boils down to one essential question: Should search engines or should courts determine Web sites’ relevancy? “If KinderStart were right … neither Google nor any other search engine could operate, as it would constantly face lawsuits from businesses seeking more favorable positioning,” Google’s motion reads.
Google also asks the judge to strike three of the suit’s counts, alleging they violate Google’s exercise of free speech in connection with a public issue. This is prohibited under a California law called the Anti-SLAPP statute, Google argues.
KinderStart.com , based in Norwalk, Calif., began publishing a Web site for parents of children under 7 years old in May 2000 and in 2003 the site joined Google’s AdSense ad network, according to the complaint. Yet, starting in March and April 2005, the Web site suffered a “cataclysmic” fall in traffic of about 70 percent and a drop in AdSense revenue of about 80 percent, from which it hasn’t recovered, and which the company blames on its removal from the Google index.
KinderStart.com claims it has never been notified by phone, mail or in person of the reason for its Web site’s exclusion. Google states in its Web site that it reserves the right to remove Web sites from its index for various reasons. KinderStart.com states it hasn’t knowingly violated any of Google’s webmaster guidelines.
In February, Google decided to remove the German Web site of car maker BMW for allegedly trying to deceive its search robot to gain higher placement. Days later Google reincorporated the site to its index, saying BMW had undone the offending changes, although BMW never admitted any wrongdoing.
Google will try to convince a judge on Friday to dismiss a lawsuit that challenges the heart of the company’s business: its methods for indexing and ranking Web pages.
In March, Google was sued by KinderStart.com , which alleges it suffered crippling financial harm after its Web site got dropped from the search engine’s index.
The case reflects the enormous impact of search engines on the business world at large. It has become crucial for many businesses to rank well in search engine results. An entire industry has sprouted to serve this “search engine optimization” need.
As the world’s most popular search engine, Google wields the strongest influence. Having a Web site that ranks low or disappears altogether from the Google index can have devastating effects for a company. This is what KinderStart.com alleges happened to it.
“It’s a very important case for many reasons. Everyone uses search engines, so the question is: Are you seeing true and faithful results?” said Gregory Yu, KinderStart.com’s attorney.
“Google shouldn’t have completely free range to be able to remove sites or hit them with a zero PageRank,” he added, referring to the patented technology at the heart of Google’s algorithmic ranking.
KinderStart.com is charging Google, among other things, with violating its right to free speech; illegally using a monopoly position to harm competitors; engaging in unfair practices and competition; committing defamation and libel; and violating the Federal Communications Act.
The Web publisher seeks a class action certification for the lawsuit, damages and injunctive relief, among other things.
In motions filed in May, Google argues that Judge Jeremy Fogel, of the U.S. District Court for the Northern District of California, San Jose Division, should dismiss the lawsuit, saying that the case boils down to one essential question: Should search engines or should courts determine Web sites’ relevancy? “If KinderStart were right … neither Google nor any other search engine could operate, as it would constantly face lawsuits from businesses seeking more favorable positioning,” Google’s motion reads.
Google also asks the judge to strike three of the suit’s counts, alleging they violate Google’s exercise of free speech in connection with a public issue. This is prohibited under a California law called the Anti-SLAPP statute, Google argues.
KinderStart.com , based in Norwalk, Calif., began publishing a Web site for parents of children under 7 years old in May 2000 and in 2003 the site joined Google’s AdSense ad network, according to the complaint. Yet, starting in March and April 2005, the Web site suffered a “cataclysmic” fall in traffic of about 70 percent and a drop in AdSense revenue of about 80 percent, from which it hasn’t recovered, and which the company blames on its removal from the Google index.
KinderStart.com claims it has never been notified by phone, mail or in person of the reason for its Web site’s exclusion. Google states in its Web site that it reserves the right to remove Web sites from its index for various reasons. KinderStart.com states it hasn’t knowingly violated any of Google’s webmaster guidelines.
In February, Google decided to remove the German Web site of car maker BMW for allegedly trying to deceive its search robot to gain higher placement. Days later Google reincorporated the site to its index, saying BMW had undone the offending changes, although BMW never admitted any wrongdoing.
Saturday, June 17, 2006
Google on secret mission to beat rivals
By Catherine Elsworth
Google is secretly developing what is thought to be one of the world’s most powerful supercomputers in its most ambitious attempt to outstrip rivals Yahoo and Microsoft.
The internet firm is building a vast complex the size of two football pitches with cooling towers four floors high on a remote stretch of barren land in Oregon.
It is thought to house two huge data centres and thousands of Google servers that will help power the billions of search queries it handles daily as well as an expanding range of other services.
The secret expansion on the 12-hectare site 129km east of Portland is thought to be part of an “arms race” as other online companies vie for Google’s crown. Microsoft has unexpectedly announced it is to spend £1.08 billion (Dh7.3 billion) next year, largely aimed at making up ground on Google. Bill Gates’s company intends to quadruple its number of internet servers to 800,000 in 25 locations across the globe by 2011.
Google, which currently runs 450,000 servers worldwide, will boost its capacity with an injection of £814 million (Dh5,502 million).Microsoft and Yahoo have also announced plans to build multi-billion-dollar data centres elsewhere in the Pacific North West, which is home to cheap electricity from hydropower and existing data networks.
The scope of the new Google plant, on the banks of the Columbia River in The Dalles, Oregon, appears to outstrip its rivals. It is being seen as a key part of the company’s drive to hone the fastest, most comprehensive data search system in line with its mission statement to “organise the world’s information and make it universally accessible and useful”.
Many analysts interpret Google’s ever-growing range of services as an attempt to muscle in on territory historically dominated by its rivals such as computer operating systems, online shopping, e-mail, music and video technology.
The new Google “power plant” is shrouded in secrecy. Known as Project 02, it has already created hundreds of jobs.The new Oregon centre will form just a part of Google’s global computing system, called the Googleplex, which is growing at such a rapid rate its exact size remains a constant topic of speculation. The company recently opened a similar data centre in Atlanta, Georgia, amid comparable secrecy.
The building has no signs or logos and local authorities are pledged to silence.
Additional Post Script from Visionefx:
Googlebot will rule the earth. - sigh...
Google is secretly developing what is thought to be one of the world’s most powerful supercomputers in its most ambitious attempt to outstrip rivals Yahoo and Microsoft.
The internet firm is building a vast complex the size of two football pitches with cooling towers four floors high on a remote stretch of barren land in Oregon.
It is thought to house two huge data centres and thousands of Google servers that will help power the billions of search queries it handles daily as well as an expanding range of other services.
The secret expansion on the 12-hectare site 129km east of Portland is thought to be part of an “arms race” as other online companies vie for Google’s crown. Microsoft has unexpectedly announced it is to spend £1.08 billion (Dh7.3 billion) next year, largely aimed at making up ground on Google. Bill Gates’s company intends to quadruple its number of internet servers to 800,000 in 25 locations across the globe by 2011.
Google, which currently runs 450,000 servers worldwide, will boost its capacity with an injection of £814 million (Dh5,502 million).Microsoft and Yahoo have also announced plans to build multi-billion-dollar data centres elsewhere in the Pacific North West, which is home to cheap electricity from hydropower and existing data networks.
The scope of the new Google plant, on the banks of the Columbia River in The Dalles, Oregon, appears to outstrip its rivals. It is being seen as a key part of the company’s drive to hone the fastest, most comprehensive data search system in line with its mission statement to “organise the world’s information and make it universally accessible and useful”.
Many analysts interpret Google’s ever-growing range of services as an attempt to muscle in on territory historically dominated by its rivals such as computer operating systems, online shopping, e-mail, music and video technology.
The new Google “power plant” is shrouded in secrecy. Known as Project 02, it has already created hundreds of jobs.The new Oregon centre will form just a part of Google’s global computing system, called the Googleplex, which is growing at such a rapid rate its exact size remains a constant topic of speculation. The company recently opened a similar data centre in Atlanta, Georgia, amid comparable secrecy.
The building has no signs or logos and local authorities are pledged to silence.
Additional Post Script from Visionefx:
Googlebot will rule the earth. - sigh...
Monday, May 29, 2006
Aussie search engine 'wows' Google

By Stephen Hutcheon
A senior Google engineer has told how he was "wowed" by an Australian search engine tool developed at the University of New South Wales.
"I think it's pretty special," said Mr Rob Pike, a principal engineer at the world's leading internet search company, speaking about the Orion search engine process.
Earlier this year, Google bought the rights to the advanced text search algorithm for an undisclosed sum and hired the doctoral student who developed it, Mr Ori Allon.
Mr Pike, who splits his year between Google's headquarters in Mountain View, California and the Sydney office, says he often visits universities and checks out research projects.
"[But] this is the first time I've walked out and said: 'Wow! We should buy this stuff'. So it's pretty unique," Mr Pike said in an interview.
In a nutshell, Orion improves the relevance of responses to a search - and displays a more detailed taste of each file so users can better decide if it is what they need.
The results of the query are displayed immediately in the form of expanded text extracts, giving the searcher the relevant information without having to go to the website - although there is still that option.
Mr Allon was born and raised in Israel and came to Australia in the mid-'90s. He is now an Australian citizen and says he one day hopes to return to his adopted country.
After completing his bachelor and masters degrees at Melbourne's Monash University, he moved to UNSW to further his studies and research.
Mr Allon's PhD supervisor, Dr Eric Martin, will continue to do some work on the project at the UNSW's Sydney campus. Although Mr Allon developed the process, the university still owns the intellectual property rights.
Speaking at the opening of Google Sydney offices earlier this month, Mr Pike says while he played no direct role in hiring Mr Allon or buying the rights to the algorithm, he acted as the "matchmaker".
Late last year he and a colleague, Dr Lars Rasmussen, attended a function at the university awhere Mr Allon demonstrated his search tool.
"We were very impressed," Mr Pike said. "So I emailed the Mountain View folks and said 'you should check this out'."
A few months later, Mr Pike bumped in to Mr Allon at the Google headquarters. "It turns out we hired him."
Mr Pike, who is an industry veteran with a long list of credits to his name, said that because Orion was "so unusual" he could not say for sure how long it would take to bring Mr Allon's work into day to day operation.
"You have to make a decision whether it's a new product or you integrate it with an existing product," Mr Pike said. "It takes time to work these things out."
Dr Rasmussen, Google Australia's head of engineering, says he was similarly impressed with Mr Allon and his search process.
"I remember meeting him [at the university last year] and then being very excited when I heard he was working for Google in Mountain View."
Google is the world's leading search engine. In April, it held a 43.1 per cent U.S. market share compared with Yahoo's 28 per cent share. Microsoft's MSN is third.
Earlier this month, Google's CEO, Mr Eric Schmidt told reporters that his company wants to maintain its dominance in the search area by making a "heavy, heavy investment in new search algorithms".
(An algorithm is a problem-solving computational procedure and is the building block for all search engines.)
Mr. Schmidt said that although the company had expanded in many directions, its core focus was still in search and search-related advertising.
"We have more people working on search than ever before," the New York Times quoted him as saying. "You will see better search, more personal search and more international search."
He said Google engineers were being encouraged to spend 70 per cent of their time on search-related projects.
"You have to make a decision whether it's a new product or you integrate it with an existing product," Mr Pike said. "It takes time to work these things out."
Dr Rasmussen, Google Australia's head of engineering, says he was similarly impressed with Mr Allon and his search process.
"I remember meeting him [at the university last year] and then being very excited when I heard he was working for Google in Mountain View."
Google is the world's leading search engine. In April, it held a 43.1 per cent U.S. market share compared with Yahoo's 28 per cent share. Microsoft's MSN is third.
Earlier this month, Google's CEO, Mr Eric Schmidt told reporters that his company wants to maintain its dominance in the search area by making a "heavy, heavy investment in new search algorithms".
(An algorithm is a problem-solving computational procedure and is the building block for all search engines.)
Mr. Schmidt said that although the company had expanded in many directions, its core focus was still in search and search-related advertising.
"We have more people working on search than ever before," the New York Times quoted him as saying. "You will see better search, more personal search and more international search."
He said Google engineers were being encouraged to spend 70 per cent of their time on search-related projects.
Tuesday, May 02, 2006
More On Amazon Dumping Google & Missing Paid Listings
By Danny Sullivan of Search Engine Watch
Barry noted yesterday that Amazon's A9 was no longer carrying Google results. More important, this means that Amazon itself no longer carries Google's search results -- and in particular, Google's paid listings.
Google and Amazon partnered back in 2003 for Amazon to offer Google searches on the Amazon site. Google ads also were displayed there. I'm pretty sure at one point, the Google logo was on Amazon's home page, along with a search box. Unfortunately, the Internet Archive simply serves up pages from 2000 no matter what links I try from the years 2003 through 2005 to check on this.
Anyway, these days, there's a small A9 Web Search box in the upper right-hand corner of the Amazon site. Until last week, that box brought back A9 results that were powered by Google. Now they are powered by Microsoft's Windows Live Search.
Few people use A9 -- but many more use Amazon. How many did web searches at Amazon is unclear, but in either place, they are no longer seeing the paid listings that Google also used to provide.
In addition, I'm also pretty certain that an ordinary Amazon search (which lots and lots of people do) used to bring up Google paid listings as part of Amazon search results. Today, I don't see these at all. Over at Threadwatch, others report not seeing these either.
MSN syndicates Search to Amazon from the Seattle Post-Intelligencer has more on the new Amazon-Microsoft agreement. The issue of who is providing paid listings isn't covered, but since the Amazon-Google agreement wasn't renewed, I'd assume these are to come from Microsoft.
Amazon Search Finds Microsoft from the Washington Post also has some details on the move, including the inspiring answer to whether Amazon felt Microsoft was providing better search results: "It will be up to users to try that out." So more a business move than a relevancy issue, fair to say :)
Udi Manber Leaves A9 to Join Google from us earlier covers A9 losing its first CEO Udi Manber to Google in February.
Barry noted yesterday that Amazon's A9 was no longer carrying Google results. More important, this means that Amazon itself no longer carries Google's search results -- and in particular, Google's paid listings.
Google and Amazon partnered back in 2003 for Amazon to offer Google searches on the Amazon site. Google ads also were displayed there. I'm pretty sure at one point, the Google logo was on Amazon's home page, along with a search box. Unfortunately, the Internet Archive simply serves up pages from 2000 no matter what links I try from the years 2003 through 2005 to check on this.
Anyway, these days, there's a small A9 Web Search box in the upper right-hand corner of the Amazon site. Until last week, that box brought back A9 results that were powered by Google. Now they are powered by Microsoft's Windows Live Search.
Few people use A9 -- but many more use Amazon. How many did web searches at Amazon is unclear, but in either place, they are no longer seeing the paid listings that Google also used to provide.
In addition, I'm also pretty certain that an ordinary Amazon search (which lots and lots of people do) used to bring up Google paid listings as part of Amazon search results. Today, I don't see these at all. Over at Threadwatch, others report not seeing these either.
MSN syndicates Search to Amazon from the Seattle Post-Intelligencer has more on the new Amazon-Microsoft agreement. The issue of who is providing paid listings isn't covered, but since the Amazon-Google agreement wasn't renewed, I'd assume these are to come from Microsoft.
Amazon Search Finds Microsoft from the Washington Post also has some details on the move, including the inspiring answer to whether Amazon felt Microsoft was providing better search results: "It will be up to users to try that out." So more a business move than a relevancy issue, fair to say :)
Udi Manber Leaves A9 to Join Google from us earlier covers A9 losing its first CEO Udi Manber to Google in February.
Saturday, April 22, 2006
Screenshots Of Google’s New Search Results Screen
It appears that search engines are all doing some redesigns:
Yahoo is working on a new homepage, Microsoft is working on Windows Live, and now Google is redesigning their search layout. The new layout will provide more information to users about a site simply by selecting the expandable arrow. Once the arrow is selected then more information will be displayed about the site, including a longer description/summary and a related image. They will also include related links to that site to help users find the information they are looking for more quickly.
This is a good idea by Google because they are not cluttering up the page and at the same time they are providing more information. Here are some screenshots on what to expect:



Yahoo is working on a new homepage, Microsoft is working on Windows Live, and now Google is redesigning their search layout. The new layout will provide more information to users about a site simply by selecting the expandable arrow. Once the arrow is selected then more information will be displayed about the site, including a longer description/summary and a related image. They will also include related links to that site to help users find the information they are looking for more quickly.
This is a good idea by Google because they are not cluttering up the page and at the same time they are providing more information. Here are some screenshots on what to expect:
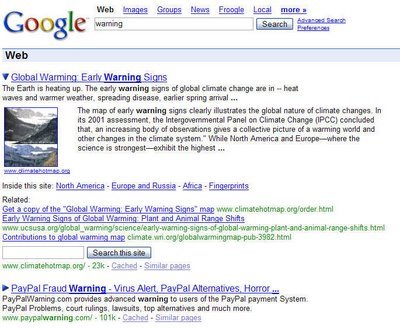


Friday, April 21, 2006
Google and the Orion Algorithm
Google Inc. has acquired "Orion" search engine technology from an Australian university that last year described the product as potentially revolutionary.
The software's inventor, Ori Allon, is now an employee of Google. "Orion" is a complement for queries running on search engines such Google, Yahoo Inc. and MSN Search.
Orion provides an expanded text excerpt from the list of web site results so the user does not have to click over multiple web pages to see the information relevant to a search query. It also displays results which are topically related to the keywords the user entered. This helps you gain additional information you might not have originally conceived, thus offering an expert search without having an expert's knowledge.
What Will the Search Results Look Like?
Search engine companies recognize that their engines need to move away from the model of providing long lists of search results, and instead aim to provide the specific facts users want. To varying degrees, major search engines deliver a digest of information collated from various online sources, particularly for queries involving news, weather, movies, actors, celebrities, and geographical locations.
To some degree Ask.com provides this function. Go to Ask.com and search ‘Virginia’. On the left there are alternative categories related to ‘Virginia’ under ‘Narrow Your Search’, ‘Expand Your Search’ and ‘Related Names’. I wonder what the ‘big three’ search engines are going to do with their sponsored ad space? I doubt Google will depart from their right-side browser display. If results are included in the organic or main text display area, then we are looking at expanded page scroll.
How Can I Prepare for the Orion Algorithm?
We do not believe that the implementation of ‘Orion’ will negatively impact web sites that have good ranking, quality links and great content. In fact, links and content will even become a more important issue to consider. A few basic search engine optimization rules will never change, that the consistent amount of traffic a web site receives in combination with textual content, in-bound links and out-bound links will remain the benchmark for good ranking.
About the Author
Ricardo Vidallon is owner and creative director for http://www.visionefx.net
The software's inventor, Ori Allon, is now an employee of Google. "Orion" is a complement for queries running on search engines such Google, Yahoo Inc. and MSN Search.
Orion provides an expanded text excerpt from the list of web site results so the user does not have to click over multiple web pages to see the information relevant to a search query. It also displays results which are topically related to the keywords the user entered. This helps you gain additional information you might not have originally conceived, thus offering an expert search without having an expert's knowledge.
What Will the Search Results Look Like?
Search engine companies recognize that their engines need to move away from the model of providing long lists of search results, and instead aim to provide the specific facts users want. To varying degrees, major search engines deliver a digest of information collated from various online sources, particularly for queries involving news, weather, movies, actors, celebrities, and geographical locations.
To some degree Ask.com provides this function. Go to Ask.com and search ‘Virginia’. On the left there are alternative categories related to ‘Virginia’ under ‘Narrow Your Search’, ‘Expand Your Search’ and ‘Related Names’. I wonder what the ‘big three’ search engines are going to do with their sponsored ad space? I doubt Google will depart from their right-side browser display. If results are included in the organic or main text display area, then we are looking at expanded page scroll.
How Can I Prepare for the Orion Algorithm?
We do not believe that the implementation of ‘Orion’ will negatively impact web sites that have good ranking, quality links and great content. In fact, links and content will even become a more important issue to consider. A few basic search engine optimization rules will never change, that the consistent amount of traffic a web site receives in combination with textual content, in-bound links and out-bound links will remain the benchmark for good ranking.
About the Author
Ricardo Vidallon is owner and creative director for http://www.visionefx.net
Tuesday, April 18, 2006
GOOGLE ACQUIRES AUSTRALIAN TECHNOLOGY
 MOUNTAIN VIEW - 04/17/06 - Google Inc. has acquired "Orion" search engine technology from an Australian university that the institution described last year as potentially revolutionary, reports the IDG News Service.
MOUNTAIN VIEW - 04/17/06 - Google Inc. has acquired "Orion" search engine technology from an Australian university that the institution described last year as potentially revolutionary, reports the IDG News Service.Google has also reportedly hired the PhD student who developed the technology. The Orion acquisition and Allon's hiring happened "months ago," the spokesman wrote, but news about this issue began to surface in recent days, starting with reports from media outlets in Australia and Israel, the student's native country, IDG rexcently reported.
In a press release issued last September, the University of New South Wales in Sydney called "Orion" a "complement for queries run on search engines such as ones from Google, Yahoo Inc. and Microsoft Corp."
Orion provides an expanded text excerpt from the list of Web site results, so that the user doesn't necessarily have to click over to those pages to see the information relevant to his query, according to the university, the release said.
It also displays results which are topically related to the keywords the user entered, even if those keywords aren't found in those related pages "thus offering an expert search without having an expert's knowledge," according to the statement.
The functionality, as described, seems to resemble a feature other search engines already offer by suggesting alternative queries to refine search results.
For example, when users run a query on IAC/InterActiveCorp's Ask.com, they get a conventional list of results, but they also receive a list of suggestions for narrowing and expanding the query's thematic scope. They also get a list of keywords that are potentially related to the query.
Through such features, search engines aim to address the problem of queries that return hundreds of thousands and even millions of results, forcing users to wade through many Web pages to find the information they are seeking.
Search engine operators recognize that their engines need to move away from the model of providing long lists of search results, and instead aim to provide the specific facts users want, say industry analysts.
To different degrees, most major search engines now sometimes deliver a digest of information collated from various online sources, particularly for queries involving weather, movies, famous people, and geographical locations.
Thursday, April 06, 2006
Google Algorithm Problems
by Rodney Ringler
Have you noticed anything different with Google lately? The Webmaster community certainly has, and if recent talk on several search engine optimization (SEO) forums is an indicator, Webmasters are very frustrated. For approximately two years Google has introduced a series of algorithm and filter changes that have led to unpredictable search engine results, and many clean (non-spam) websites have been dropped from the rankings. Google updates used to be monthly, and then quarterly. Now with so many servers, there seems to be several different search engine results rolling through the servers at any time during a quarter. Part of this is the recent Big Daddy update, which is a Google infrastructure update as much as an algorithm update. We believe Big Daddy is using a 64 bit architecture. Pages seem to go from a first page ranking to a spot on the 100th page, or worse yet to the Supplemental index. Google algorithm changes started in November 2003 with the Florida update, which now ranks as a legendary event in the Webmaster community. Then came updates named Austin, Brandy, Bourbon, and Jagger. Now we are dealing with the BigDaddy!
The algorithm problems seem to fall into 4 categories. There are canonical issues, duplicate content issues, the Sandbox, and supplemental page issues
1. Canonical Issues: These occur when a search engine treats www.yourdomain.com, yourdomain.com, and yourdomain.com/index.html all as different websites. When Google does this, it then flags the different copies as duplicate content and penalizes them. Also, if the site not penalized is http://yourdomain.com, but all of the websites link to your website using www.yourdomain.com, then the version left in the index will have no ranking. These are basic issues that other major search engines, such as Yahoo and MSN, have no problem dealing with. Google is possibly the greatest search engine in the world (ranking themselves as a 10 on a scale of 1 to 10). They provide tremendous results for a wide range of topics, and yet they cannot get some basic indexing issues resolved.
2. The Sandbox: This has become one of the legends of the search engine world. It appears that websites, or links to them, are "sandboxed" for a period before they are given full rank in the index, kind of like a maturing time. Some even think it is only applied to a set of competitive keywords, because they were the ones being manipulated the most. The Sandbox existence is debated, and Google has never officially confirmed it. The hypothesis behind the Sandbox is that Google knows that someone cannot create a 100,000 page website overnight, so they have implemented a type of time penalty for new links and sites before fully making the index.
3. Duplicate Content Issues: These have become a major issue on the Internet. Because web pages drive search engine rankings, black hat SEOs (search engine optimizers) started duplicating entire sites' content under their own domain name, thereby instantly producing a ton of web pages (an example of this would be to download an Encyclopedia onto your website). As a result of this abuse, Google aggressively attacked duplicate content abusers with their algorithm updates. But in the process they knocked out many legitimate sites as collateral damage. One example occurs when someone scrapes your website. Google sees both sites and may determine the legitimate one to be the duplicate. About the only thing a Webmaster can do is track down these sites as they are scraped, and submit a spam report to Google. Another big issue with duplicate content is that there are a lot of legitimate uses of duplicate content. News feeds are the most obvious example. A news story is covered by many websites because it is content the viewers want. Any filter will inevitably catch some legitimate uses.
4. Supplemental Page Issues: Webmasters fondly refer to this as Supplemental Hell. This issue has been reported on places like WebmasterWorld for over a year, but a major shake up around February 23rd has led to a huge outcry from the Webmaster community. This recent shakeup was part of the ongoing BigDaddy rollout that should finish this month. This issue is still unclear, but here is what we know. Google has 2 indexes: the Main index that you get when you search, and the Supplemental index that contains pages that are old, no longer active, have received errors, etc. The Supplemental index is a type of graveyard where web pages go when they are no longer deemed active. No one disputes the need for a Supplemental index. The problem, though, is that active, recent, and clean pages have been showing up in the Supplemental index. Like a dungeon, once they go in, they rarely come out. This issue has been reported with a low noise level for over a year, but the recent February upset has led to a lot of discussion around it. There is not a lot we know about this issue, and no one can seem to find a common cause leading to it.
Google updates were once fairly predictable, with monthly updates that Webmasters anticipated with both joy and angst. Google followed a well published algorithm that gave each website a Page Rank, which is a number given to each webpage based on the number and rank of other web pages pointing to it. When someone searches on a term, all of the web pages deemed relevant are then ordered by their Page Rank.
Google uses a number of factors such as keyword density, page titles, meta tags, and header tags to determine which pages are relevant. This original algorithm favored incoming links and the anchor text of them. The more links you got with an anchor text, the better you ranked for that keyword. As Google gained the bulk of internet searches in the early part of the decade, ranking well in their engine became highly coveted. Add to this the release of Google's Adsense program, and it became very lucrative. If a website could rank high for a popular keyword, they could run Google ads under Adsense and split the revenue with Google!
This combination led to an avalanche of SEO'ing like the Webmaster world had never seen. The whole nature of links between websites changed. Websites used to link to one another because it was good information for their visitors. But now that link to another website could reduce your search engine rankings, and if it is a link to a competitor, it might boost his. In Google's algorithm, links coming into your website boost the site's PageRank (PR), while links from your web pages to other sites reduce your PR. People started creating link farms, doing reciprocal link partnerships, and buying/selling links. Webmasters started linking to each other for mutual ranking help or money, instead of quality content for their visitors. This also led to the wholesale scraping of websites. Black hat SEO's will take the whole content of a website, put Google's ad on it, get a few high powered incoming links, and the next thing you know they are ranking high in Google and generating revenue from Google's Adsense without providing any unique website content.
Worse yet, as Google tries to go after this duplicate content, they sometimes get the real company instead of the scraper. This is all part of the cat and mouse game that has become the Google algorithm. Once Google realized the manipulation that was happening, they decided to aggressively alter their algorithms to prevent it. After all, their goal is to find the most relevant results for their searchers. At the same time, they also faced huge growth with the internet explosion. This has led to a period of unstable updates, causing many top ranking websites to disappear while many spam and scraped websites remain. In spite of Google's efforts, every change seems to catch more quality websites. Many spam sites and websites that violate Google's guidelines are caught, but there is an endless tide of more spam websites taking their place.
Some people might believe that this is not a problem. Google is there to provide the best relevant listings for what people are searching on, and for the most part the end user has not noticed an issue with Google's listings. If they only drop thousands of listings out of millions, then the results are still very good. These problems may not be affecting Google's bottom line now, but having a search engine that cannot be evolved without producing unintended results will hurt them over time in several ways.
First, as the competition from MSN and Yahoo grows, having the best results will no longer be a given, and these drops in quality listings will hurt them. Next, to stay competitive Google will need to continue to change their algorithms. This will be harder if they cannot make changes without producing unintended results. Finally, having the Webmaster community lose faith in them will make them vulnerable to competition. Webmasters provide Google with two things. They are the word of mouth experts. Also, they run the websites that use Google's Adsense program. Unlike other monopolies, it is easy to switch search engines. People might also criticize Webmasters for relying on a business model that requires free search engine traffic. Fluctuations in ranking are part of the internet business, and most Webmasters realize this. Webmasters are simply asking Google to fix bugs that cause unintended issues with their sites.
Most Webmasters may blame ranking losses on Google and their bugs. But the truth is that many Webmasters do violate some of the guidelines that Google lays out. Most consider it harmless to bend the rules a little, and assume this is not the reason their websites have issues. In some cases, though, Google is right and has just tweaked its algorithm in the right direction. Here is an example: Google seems to be watching the incoming links to your site to make sure they don't have the same anchor text (this is the text used in the link on the website linking to you). If too many links use the same anchor text, Google discounts these links. This was originally done by some people to inflate their rankings. Other people did it because one anchor text usually makes sense. This is not really a black hat SEO trick, and it is not called out in Google's guidelines, but it has caused some websites to lose rank.
Webmasters realize that Google needs to fight spam and black hat SEO manipulation. And to their credit, there is a Google Engineer named Matt Cutts who has a Blog site and participates in SEO forums to assist Webmasters. But given the revenue impact that Google rankings have on companies, Webmasters would like to see even more communication around the known issues, and help with identifying future algorithm issues. No one expects Google to reveal their algorithm or what changes they are making. Rumor on the forum boards speculates that Google is currently looking at items like the age of the domain name, websites on the same IP, and frequency of fresh content. It would be nice from a Webmaster standpoint to be able to report potential bugs to Google, and get a response. It is in Google's best interest to have a bug free algorithm. This will in turn provide the best search engine results for everyone.
About The AuthorRodney Ringler is President of Advantage1 Web Services, Inc., which owns a network of Web Hosting Informational Websites including Hostchart.com, Resellerconnection.com, Foundhost.com and Resellerforums.com.
Have you noticed anything different with Google lately? The Webmaster community certainly has, and if recent talk on several search engine optimization (SEO) forums is an indicator, Webmasters are very frustrated. For approximately two years Google has introduced a series of algorithm and filter changes that have led to unpredictable search engine results, and many clean (non-spam) websites have been dropped from the rankings. Google updates used to be monthly, and then quarterly. Now with so many servers, there seems to be several different search engine results rolling through the servers at any time during a quarter. Part of this is the recent Big Daddy update, which is a Google infrastructure update as much as an algorithm update. We believe Big Daddy is using a 64 bit architecture. Pages seem to go from a first page ranking to a spot on the 100th page, or worse yet to the Supplemental index. Google algorithm changes started in November 2003 with the Florida update, which now ranks as a legendary event in the Webmaster community. Then came updates named Austin, Brandy, Bourbon, and Jagger. Now we are dealing with the BigDaddy!
The algorithm problems seem to fall into 4 categories. There are canonical issues, duplicate content issues, the Sandbox, and supplemental page issues
1. Canonical Issues: These occur when a search engine treats www.yourdomain.com, yourdomain.com, and yourdomain.com/index.html all as different websites. When Google does this, it then flags the different copies as duplicate content and penalizes them. Also, if the site not penalized is http://yourdomain.com, but all of the websites link to your website using www.yourdomain.com, then the version left in the index will have no ranking. These are basic issues that other major search engines, such as Yahoo and MSN, have no problem dealing with. Google is possibly the greatest search engine in the world (ranking themselves as a 10 on a scale of 1 to 10). They provide tremendous results for a wide range of topics, and yet they cannot get some basic indexing issues resolved.
2. The Sandbox: This has become one of the legends of the search engine world. It appears that websites, or links to them, are "sandboxed" for a period before they are given full rank in the index, kind of like a maturing time. Some even think it is only applied to a set of competitive keywords, because they were the ones being manipulated the most. The Sandbox existence is debated, and Google has never officially confirmed it. The hypothesis behind the Sandbox is that Google knows that someone cannot create a 100,000 page website overnight, so they have implemented a type of time penalty for new links and sites before fully making the index.
3. Duplicate Content Issues: These have become a major issue on the Internet. Because web pages drive search engine rankings, black hat SEOs (search engine optimizers) started duplicating entire sites' content under their own domain name, thereby instantly producing a ton of web pages (an example of this would be to download an Encyclopedia onto your website). As a result of this abuse, Google aggressively attacked duplicate content abusers with their algorithm updates. But in the process they knocked out many legitimate sites as collateral damage. One example occurs when someone scrapes your website. Google sees both sites and may determine the legitimate one to be the duplicate. About the only thing a Webmaster can do is track down these sites as they are scraped, and submit a spam report to Google. Another big issue with duplicate content is that there are a lot of legitimate uses of duplicate content. News feeds are the most obvious example. A news story is covered by many websites because it is content the viewers want. Any filter will inevitably catch some legitimate uses.
4. Supplemental Page Issues: Webmasters fondly refer to this as Supplemental Hell. This issue has been reported on places like WebmasterWorld for over a year, but a major shake up around February 23rd has led to a huge outcry from the Webmaster community. This recent shakeup was part of the ongoing BigDaddy rollout that should finish this month. This issue is still unclear, but here is what we know. Google has 2 indexes: the Main index that you get when you search, and the Supplemental index that contains pages that are old, no longer active, have received errors, etc. The Supplemental index is a type of graveyard where web pages go when they are no longer deemed active. No one disputes the need for a Supplemental index. The problem, though, is that active, recent, and clean pages have been showing up in the Supplemental index. Like a dungeon, once they go in, they rarely come out. This issue has been reported with a low noise level for over a year, but the recent February upset has led to a lot of discussion around it. There is not a lot we know about this issue, and no one can seem to find a common cause leading to it.
Google updates were once fairly predictable, with monthly updates that Webmasters anticipated with both joy and angst. Google followed a well published algorithm that gave each website a Page Rank, which is a number given to each webpage based on the number and rank of other web pages pointing to it. When someone searches on a term, all of the web pages deemed relevant are then ordered by their Page Rank.
Google uses a number of factors such as keyword density, page titles, meta tags, and header tags to determine which pages are relevant. This original algorithm favored incoming links and the anchor text of them. The more links you got with an anchor text, the better you ranked for that keyword. As Google gained the bulk of internet searches in the early part of the decade, ranking well in their engine became highly coveted. Add to this the release of Google's Adsense program, and it became very lucrative. If a website could rank high for a popular keyword, they could run Google ads under Adsense and split the revenue with Google!
This combination led to an avalanche of SEO'ing like the Webmaster world had never seen. The whole nature of links between websites changed. Websites used to link to one another because it was good information for their visitors. But now that link to another website could reduce your search engine rankings, and if it is a link to a competitor, it might boost his. In Google's algorithm, links coming into your website boost the site's PageRank (PR), while links from your web pages to other sites reduce your PR. People started creating link farms, doing reciprocal link partnerships, and buying/selling links. Webmasters started linking to each other for mutual ranking help or money, instead of quality content for their visitors. This also led to the wholesale scraping of websites. Black hat SEO's will take the whole content of a website, put Google's ad on it, get a few high powered incoming links, and the next thing you know they are ranking high in Google and generating revenue from Google's Adsense without providing any unique website content.
Worse yet, as Google tries to go after this duplicate content, they sometimes get the real company instead of the scraper. This is all part of the cat and mouse game that has become the Google algorithm. Once Google realized the manipulation that was happening, they decided to aggressively alter their algorithms to prevent it. After all, their goal is to find the most relevant results for their searchers. At the same time, they also faced huge growth with the internet explosion. This has led to a period of unstable updates, causing many top ranking websites to disappear while many spam and scraped websites remain. In spite of Google's efforts, every change seems to catch more quality websites. Many spam sites and websites that violate Google's guidelines are caught, but there is an endless tide of more spam websites taking their place.
Some people might believe that this is not a problem. Google is there to provide the best relevant listings for what people are searching on, and for the most part the end user has not noticed an issue with Google's listings. If they only drop thousands of listings out of millions, then the results are still very good. These problems may not be affecting Google's bottom line now, but having a search engine that cannot be evolved without producing unintended results will hurt them over time in several ways.
First, as the competition from MSN and Yahoo grows, having the best results will no longer be a given, and these drops in quality listings will hurt them. Next, to stay competitive Google will need to continue to change their algorithms. This will be harder if they cannot make changes without producing unintended results. Finally, having the Webmaster community lose faith in them will make them vulnerable to competition. Webmasters provide Google with two things. They are the word of mouth experts. Also, they run the websites that use Google's Adsense program. Unlike other monopolies, it is easy to switch search engines. People might also criticize Webmasters for relying on a business model that requires free search engine traffic. Fluctuations in ranking are part of the internet business, and most Webmasters realize this. Webmasters are simply asking Google to fix bugs that cause unintended issues with their sites.
Most Webmasters may blame ranking losses on Google and their bugs. But the truth is that many Webmasters do violate some of the guidelines that Google lays out. Most consider it harmless to bend the rules a little, and assume this is not the reason their websites have issues. In some cases, though, Google is right and has just tweaked its algorithm in the right direction. Here is an example: Google seems to be watching the incoming links to your site to make sure they don't have the same anchor text (this is the text used in the link on the website linking to you). If too many links use the same anchor text, Google discounts these links. This was originally done by some people to inflate their rankings. Other people did it because one anchor text usually makes sense. This is not really a black hat SEO trick, and it is not called out in Google's guidelines, but it has caused some websites to lose rank.
Webmasters realize that Google needs to fight spam and black hat SEO manipulation. And to their credit, there is a Google Engineer named Matt Cutts who has a Blog site and participates in SEO forums to assist Webmasters. But given the revenue impact that Google rankings have on companies, Webmasters would like to see even more communication around the known issues, and help with identifying future algorithm issues. No one expects Google to reveal their algorithm or what changes they are making. Rumor on the forum boards speculates that Google is currently looking at items like the age of the domain name, websites on the same IP, and frequency of fresh content. It would be nice from a Webmaster standpoint to be able to report potential bugs to Google, and get a response. It is in Google's best interest to have a bug free algorithm. This will in turn provide the best search engine results for everyone.
About The AuthorRodney Ringler is President of Advantage1 Web Services, Inc., which owns a network of Web Hosting Informational Websites including Hostchart.com, Resellerconnection.com, Foundhost.com and Resellerforums.com.
Tuesday, April 04, 2006
Can duplicate content influence your rankings?
Every few months, webmaster forums discuss if search engines penalize duplicate content.
Duplicate content can happen if web pages publish the same articles, if different domains point to the same web space or if webmasters steal the content of other pages. If two shops sell the same item and use similar shop systems, some product pages can also look like duplicated web pages.
Is there really a penalty for duplicate content?
There are many opinions in the discussion forums but there's no proof that search engines really penalize duplicate content.
If there really was a duplicate content filter then many news web sites that publish AP or
Reuters news would be banned from search engines. For example, you can find many web pages with exactly the same article here. All pages can be found on Google.
However, many people insist that a duplicate content filter exists.
Why do people think that there's a duplicate content penalty?
Some people think that there is a duplicate content penalty because a web page that shows a special article might have a Google PageRank 0 and another web page with the same article might have a Google PageRank 5.
Not all web pages with the same content have the same search engine rankings. If a web site is older than another, if it has better inbound links and if that site has more content than it's likely that it will get better rankings than another page that lists the same article.
That doesn't mean that the web site with the worse ranking has been penalized. It just means that the other web site probably has more links and that the page is more trustworthy to search engines.
Some people think that there must be a duplicate content filter because additional domain names that point to the same web space as the main domain name are usually not listed on search engines.
This is not due to a duplicate content filter. It's an issue with canonical URLs. Google has addressed that problem with their latest ranking algorithm update.
Whether there is a duplicate content penalty or not has yet to be proved. If you want to outperform your competition on search engines, make sure that your web site has unique content that cannot be found on other sites.
If your web site has unique content, you don't have to worry about potential duplicate content penalties. Optimize that content for search engines and make sure that your web site has good inbound links.
It's hard to beat a web site with great optimized content and many good inbound links.
Duplicate content can happen if web pages publish the same articles, if different domains point to the same web space or if webmasters steal the content of other pages. If two shops sell the same item and use similar shop systems, some product pages can also look like duplicated web pages.
Is there really a penalty for duplicate content?
There are many opinions in the discussion forums but there's no proof that search engines really penalize duplicate content.
If there really was a duplicate content filter then many news web sites that publish AP or
Reuters news would be banned from search engines. For example, you can find many web pages with exactly the same article here. All pages can be found on Google.
However, many people insist that a duplicate content filter exists.
Why do people think that there's a duplicate content penalty?
Some people think that there is a duplicate content penalty because a web page that shows a special article might have a Google PageRank 0 and another web page with the same article might have a Google PageRank 5.
Not all web pages with the same content have the same search engine rankings. If a web site is older than another, if it has better inbound links and if that site has more content than it's likely that it will get better rankings than another page that lists the same article.
That doesn't mean that the web site with the worse ranking has been penalized. It just means that the other web site probably has more links and that the page is more trustworthy to search engines.
Some people think that there must be a duplicate content filter because additional domain names that point to the same web space as the main domain name are usually not listed on search engines.
This is not due to a duplicate content filter. It's an issue with canonical URLs. Google has addressed that problem with their latest ranking algorithm update.
Whether there is a duplicate content penalty or not has yet to be proved. If you want to outperform your competition on search engines, make sure that your web site has unique content that cannot be found on other sites.
If your web site has unique content, you don't have to worry about potential duplicate content penalties. Optimize that content for search engines and make sure that your web site has good inbound links.
It's hard to beat a web site with great optimized content and many good inbound links.
Wednesday, March 29, 2006
SEO For MSN
This is article one of a four part series on optimizing your website for the "Big Three". Part two will focus on Yahoo!, Part three will focus on Google and part four of this series will explain how to perform SEO on your website to attain high rankings across all three major engines. We are beginning with MSN as rankings are generally faster attained on this engine and thus it is a good place to begin, especially if you have a new site that is likely still in the sandbox on Google or are just at the beginning stages of link building.Like all of the major search engines, MSN builds their index of sites using spiders to crawl the web finding new and changed information. This information is then processed by the MSN servers using complex algorithms to determine which sites are most relevant to the search query entered.
This may seem like an extraordinarily complex process and it is however the resulting environment is simple: all search engine algorithms are mathematical and thus, there is a fixed set of rules and factors which, if addressed correctly, will result in a high ranking. In short, because it's math we have the benefit of knowing that if we take action x and action y we will get results.
The Rules For MSN
Assuming that you are following the right rules, the results you can achieve on MSN can be fast and solid. MSN does not apply the same types of aging delays that the other two engines do and thus, when you change your content the change in results can be realized as quickly as they reindex your site and as quickly as your incoming links get picked. This differs greatly from Google and Yahoo! in that those two engines age both domains and links requiring a longer period of time before the full effects of your efforts are realized.
As an additional note on MSN, users of MSN are 48% more likely to purchase a product or service online than the average Internet user according to a comScore Media report.
So what are the rules for MSN that can help us get top rankings? As with all the major engines, there are two fundamental areas that need to be addressed to attain top rankings. The first is the onsite factors, the second is the offsite. Because they are fundamentally different we will address them separately.
Onsite SEO Factors
The problem with writing an article about the onsite factors is that by the time many of you read this some of the weight these factors hold and the optimal levels noted may well be out-of-date. Thus, rather than listing overly-specific-and-sure-to-change factors we will focus on how to know what the factors are, how to get a handle on what you need to adjust and by how much, and how to predict what will be coming down the road. And so we'll begin:
How To Know What The Factors Are:
Unfortunately there's no one over at MSN Search calling us up weekly to let us know what the specifics of their algorithm are, we have to figure it out for ourselves with research, reading and playing with test sites. From all of this there is only one conclusion that an SEO can make: the details matter. When we're discussing onsite factors this includes:
* the content of the page including keyword density
* the internal linking structure of the site (how the pages of your site are linked together)
* the number of pages in your site and the relevancy of those pages to your main topic and phrases
* the use of titles, heading tags and special formats
There are a number of lower weight factors however the ones noted above, if addressed correctly, will have very significant results on your rankings if the offsite factors noted below are also addressed.
Page Content:
The content of your page must be perfect. What I mean by this is that the content must appeal to both the search engines and the algorithms. In order to write properly for the visitors you must be able to write clearly and in language that is both appealing and understandable to your target market. While there is much debate about whether the keyword density of your page is important I am certainly one who believes that it is. It only makes sense that a part of the algorithm takes into account the use of the keywords on your page. Unfortunately the optimal keyword density changes slightly with each algorithm update and also by site type and field. For this reason it would be virtually impossible for me to give you a density that will work today and forevermore. For this reason you will need a keyword density analysis tool which you will want to run on your own site as well as the sites in the top 10 to assess what the optimal density is at this time. You may notice a variation in the densities of the top 10. This is due to the other factors including offsite which can give extra weight to even a poorly optimized site. I recommend getting your site to a keyword density close to the higher-end of the top 10 but not excessive. Traditionally this percentage will fall somewhere near 3.5 to 4% for MSN.
Internal Linking Structure:
The way your pages link together tells the search engines what the page is about and also allows them to easily (or not-so-easily) work their way to your internal pages. If your site has an image or script-based navigation it is important to also use text links either in your content, in a footer, or both. The text links are easy to follow for a spider and perhaps more importantly, the text links allow you the opportunity to tell the spiders what a specific page is about though the anchor text and, in the case of footers, allows you to add in more instances of the targeted phrases outside of your general content area.
The Number Of Pages & Their Relevancy:
MSN wants to please their visitors. For this reason they want to insure that highest likelihood that a searcher will find what they need once they get to your site. For this reason a larger site with unified content will rank higher that a smaller site or a site with varying content topics. (note: this assumes that all else is equal in regards to the other ranking factors)
When you are optimizing your site for MSN be sure to take some time to built quality content. Do a search on your major competitors to see how large their sites are, over time you will want to build yours to the same range through general content creation or the addition of a blog or forum to your site.
Titles, Heading Tags & Special Formats:
Titles are the single most important piece of code our your entire web page for two reasons. The first is that it holds a very high level of weight in the algorithm. the second reason is that it is your window to the world. When someone runs a search the results will generally show your page title in the search results. This means that a human visitor has to be drawn to click on your title or rankings your site is a futile effort (this isn't about bragging rights, it's about return on investment).
Heading tags are used to specify significant portions of content. The most commonly used is the H1 tag though there are obviously others (or they wouldn't bother numbering them would they). The H1 tag is given a significant amount of weight in the algorithm provided that it is not abused though overuse (it should only be used once per page). Try to keep your headings short-and-sweet. They're there to tell your visitor what the page is about, not your whole site.
Special formats are, for the purpose of this article, and text formatting that distinguishes a set of characters or words apart from the others. This includes such things as, anchor text, bold, italic, different font colors, etc. When you set content apart using special formats MSN will read this as a part of your content that you want to draw attention to and which you obviously want your visitors to see. This will increase the weight of that content. Now don't go making all your keyword bold or the such, simply make sure to use special formats properly. Inline text links (links in the body content of your page) is a great way to increase the weight of specific text while actually helping your visitor by providing easy paths to pages they may be interested in.
Offsite SEO Factors
With MSN, the offsite factors are much simpler to deal with than either Google or Yahoo! MSN will give you full credit for a link the day they pick it up so link building, while time consuming, is reworded much quicker on MSN. When dealing with MSN and offsite SEO there are two main factors we must consider when finding links:
* Relevancy. The site must be relevant to yours to hold any real weight.
* Quality is better than quantity. Because PageRank is Google-specific we can't use it as the grading tool for MSN however upon visiting a website it's generally fairly clear whether we're visiting a good site or not. Spending extra time to find quality is well rewarded. Also, finding one-way links as opposed to reciprocal links is becoming increasingly important and I'd recommend utilizing both in your link building strategies.
You will have to begin your offsite optimization by running link checks on your competitors to see what you're up against. This is also a good place to start for potential link partners though those of you using a tool such as Total Optimizer Pro or PR Prowler will find it far faster and more effective to use these tools.
Conclusion
This entire article may seem fairly simplistic and there's a reason for that, what we've noted above is a list of the more important areas however to save you frustration and me from receiving hundreds of emails a few months from now noting that the keyword densities don't work, etc. I've tried to keep it general. Below you'll find a list of recommended resources. These are tools and SEO resources to help keep you updated and on top of the rankings.
Next week we will be covering Yahoo!
Resources
Total Optimizer Pro - A keyword density and backlink analysis tool. This tool breaks down a variety of onsite and offsite factors giving you a full snapshot of how the top 10 got their positions.
Microsoft Press Room - Read the latest press releases from Microsoft. This may not give you the algorithm but it will tell you the direction they're going. Understand this and you'll be better equipped to deal with changes down the road.
SearchEngineWatch's MSN Forums - Read the latest news, feedback and discussions on the SearchEngineWatch forums. A great way to keep updated but beware, not everyone in there is a qualified opinion.
About This Author:
Dave Davies is the CEO of the SEO services firm Beanstalk Search Engine Positioning, Inc. Beanstalk provides guaranteed search engine positioning and SEO%20consulting[/url'>services to clients from around the world. If you're more interested in doing it yourself please visit our [url=http://www.beanstalk-inc.com/blog/]SEO news blog to keep updated on the latest goings-on in the search engine world.
This may seem like an extraordinarily complex process and it is however the resulting environment is simple: all search engine algorithms are mathematical and thus, there is a fixed set of rules and factors which, if addressed correctly, will result in a high ranking. In short, because it's math we have the benefit of knowing that if we take action x and action y we will get results.
The Rules For MSN
Assuming that you are following the right rules, the results you can achieve on MSN can be fast and solid. MSN does not apply the same types of aging delays that the other two engines do and thus, when you change your content the change in results can be realized as quickly as they reindex your site and as quickly as your incoming links get picked. This differs greatly from Google and Yahoo! in that those two engines age both domains and links requiring a longer period of time before the full effects of your efforts are realized.
As an additional note on MSN, users of MSN are 48% more likely to purchase a product or service online than the average Internet user according to a comScore Media report.
So what are the rules for MSN that can help us get top rankings? As with all the major engines, there are two fundamental areas that need to be addressed to attain top rankings. The first is the onsite factors, the second is the offsite. Because they are fundamentally different we will address them separately.
Onsite SEO Factors
The problem with writing an article about the onsite factors is that by the time many of you read this some of the weight these factors hold and the optimal levels noted may well be out-of-date. Thus, rather than listing overly-specific-and-sure-to-change factors we will focus on how to know what the factors are, how to get a handle on what you need to adjust and by how much, and how to predict what will be coming down the road. And so we'll begin:
How To Know What The Factors Are:
Unfortunately there's no one over at MSN Search calling us up weekly to let us know what the specifics of their algorithm are, we have to figure it out for ourselves with research, reading and playing with test sites. From all of this there is only one conclusion that an SEO can make: the details matter. When we're discussing onsite factors this includes:
* the content of the page including keyword density
* the internal linking structure of the site (how the pages of your site are linked together)
* the number of pages in your site and the relevancy of those pages to your main topic and phrases
* the use of titles, heading tags and special formats
There are a number of lower weight factors however the ones noted above, if addressed correctly, will have very significant results on your rankings if the offsite factors noted below are also addressed.
Page Content:
The content of your page must be perfect. What I mean by this is that the content must appeal to both the search engines and the algorithms. In order to write properly for the visitors you must be able to write clearly and in language that is both appealing and understandable to your target market. While there is much debate about whether the keyword density of your page is important I am certainly one who believes that it is. It only makes sense that a part of the algorithm takes into account the use of the keywords on your page. Unfortunately the optimal keyword density changes slightly with each algorithm update and also by site type and field. For this reason it would be virtually impossible for me to give you a density that will work today and forevermore. For this reason you will need a keyword density analysis tool which you will want to run on your own site as well as the sites in the top 10 to assess what the optimal density is at this time. You may notice a variation in the densities of the top 10. This is due to the other factors including offsite which can give extra weight to even a poorly optimized site. I recommend getting your site to a keyword density close to the higher-end of the top 10 but not excessive. Traditionally this percentage will fall somewhere near 3.5 to 4% for MSN.
Internal Linking Structure:
The way your pages link together tells the search engines what the page is about and also allows them to easily (or not-so-easily) work their way to your internal pages. If your site has an image or script-based navigation it is important to also use text links either in your content, in a footer, or both. The text links are easy to follow for a spider and perhaps more importantly, the text links allow you the opportunity to tell the spiders what a specific page is about though the anchor text and, in the case of footers, allows you to add in more instances of the targeted phrases outside of your general content area.
The Number Of Pages & Their Relevancy:
MSN wants to please their visitors. For this reason they want to insure that highest likelihood that a searcher will find what they need once they get to your site. For this reason a larger site with unified content will rank higher that a smaller site or a site with varying content topics. (note: this assumes that all else is equal in regards to the other ranking factors)
When you are optimizing your site for MSN be sure to take some time to built quality content. Do a search on your major competitors to see how large their sites are, over time you will want to build yours to the same range through general content creation or the addition of a blog or forum to your site.
Titles, Heading Tags & Special Formats:
Titles are the single most important piece of code our your entire web page for two reasons. The first is that it holds a very high level of weight in the algorithm. the second reason is that it is your window to the world. When someone runs a search the results will generally show your page title in the search results. This means that a human visitor has to be drawn to click on your title or rankings your site is a futile effort (this isn't about bragging rights, it's about return on investment).
Heading tags are used to specify significant portions of content. The most commonly used is the H1 tag though there are obviously others (or they wouldn't bother numbering them would they). The H1 tag is given a significant amount of weight in the algorithm provided that it is not abused though overuse (it should only be used once per page). Try to keep your headings short-and-sweet. They're there to tell your visitor what the page is about, not your whole site.
Special formats are, for the purpose of this article, and text formatting that distinguishes a set of characters or words apart from the others. This includes such things as, anchor text, bold, italic, different font colors, etc. When you set content apart using special formats MSN will read this as a part of your content that you want to draw attention to and which you obviously want your visitors to see. This will increase the weight of that content. Now don't go making all your keyword bold or the such, simply make sure to use special formats properly. Inline text links (links in the body content of your page) is a great way to increase the weight of specific text while actually helping your visitor by providing easy paths to pages they may be interested in.
Offsite SEO Factors
With MSN, the offsite factors are much simpler to deal with than either Google or Yahoo! MSN will give you full credit for a link the day they pick it up so link building, while time consuming, is reworded much quicker on MSN. When dealing with MSN and offsite SEO there are two main factors we must consider when finding links:
* Relevancy. The site must be relevant to yours to hold any real weight.
* Quality is better than quantity. Because PageRank is Google-specific we can't use it as the grading tool for MSN however upon visiting a website it's generally fairly clear whether we're visiting a good site or not. Spending extra time to find quality is well rewarded. Also, finding one-way links as opposed to reciprocal links is becoming increasingly important and I'd recommend utilizing both in your link building strategies.
You will have to begin your offsite optimization by running link checks on your competitors to see what you're up against. This is also a good place to start for potential link partners though those of you using a tool such as Total Optimizer Pro or PR Prowler will find it far faster and more effective to use these tools.
Conclusion
This entire article may seem fairly simplistic and there's a reason for that, what we've noted above is a list of the more important areas however to save you frustration and me from receiving hundreds of emails a few months from now noting that the keyword densities don't work, etc. I've tried to keep it general. Below you'll find a list of recommended resources. These are tools and SEO resources to help keep you updated and on top of the rankings.
Next week we will be covering Yahoo!
Resources
Total Optimizer Pro - A keyword density and backlink analysis tool. This tool breaks down a variety of onsite and offsite factors giving you a full snapshot of how the top 10 got their positions.
Microsoft Press Room - Read the latest press releases from Microsoft. This may not give you the algorithm but it will tell you the direction they're going. Understand this and you'll be better equipped to deal with changes down the road.
SearchEngineWatch's MSN Forums - Read the latest news, feedback and discussions on the SearchEngineWatch forums. A great way to keep updated but beware, not everyone in there is a qualified opinion.
About This Author:
Dave Davies is the CEO of the SEO services firm Beanstalk Search Engine Positioning, Inc. Beanstalk provides guaranteed search engine positioning and SEO%20consulting[/url'>services to clients from around the world. If you're more interested in doing it yourself please visit our [url=http://www.beanstalk-inc.com/blog/]SEO news blog to keep updated on the latest goings-on in the search engine world.
Sunday, March 19, 2006
Rant and Rave About Google
Rant and Rave About Google
The Search
I recently purchased a book called "The Search" by John Battelle that explores how Google and its rivals rewrote the rules of business and transformed our culture. What really caught my attention was Chapter 7 titled The Search Economy. It related how a small e-commerce store got yanked by the short-hairs when Google made an unexpected algorithm change in 2003 virtually wiped out their business.
Google did it again in late 2005, and will no doubt do it again and again and again. Rumor has it that it will happen again in March 2006.
Google Giveth, Google Taketh Away
Those of you who are webmasters already know how this happens. Some eager beaver group of Google engineers laid waste to thousands of mom and pop businesses by tweaking Google’s indexing algorithm. These businesses depended on their Google listings for their income and livelihoods. Google giveth and Google taketh away.
Knowing that the Google paradigm will always change puts you ahead of the pack; not putting all your marketing eggs in one basket will keep you there.
Your unpaid or "organic" rankings in search engines are free. But how many times have you heard the axiom "there's no such thing as a free lunch."
Starting to get the picture now?
Google Still Likes Links
I've been getting tons of automated requests for two-way and three-way linking. I can't believe what these people are thinking. The rules are displayed in black and white on Google's web site. Allow me to paraphrase "Build pages for users, not search engines."
Here's a typical email I get every day:
Hello Sir/Madam,I'm mailing you for exchanging three-way link with your site. Though we are accustomed with reciprocal link exchange, the fact is that three-way link is always better than reciprocal link exchange, as all search engines give more attention to three-way links.When search engines can't trace a link back from one site to another it thinks that site is very important so other site is linking to it just like we use google or yahoo in our website.
Do these bozos really believe this?
Fact of the matter is you should link to a website that you believe will be of value to your website viewer’s. That’s it. No schemes, no tricks, no 2, 3, 4, 5 or 6 way linking. Provide your visitors good content and good links. Period.
Vertical Channels and Directories
Web sites like Global Spec (for engineers) and Find Law (for lawyers) are quasi-vertical advertising channels and global directories. Vertical marketing is a great way to target business in the same genre that you practice and participate. It’s also a great way for regional companies to inexpensively obtain entry into new markets or regions.
For web guys like myself, there are similar verticals or directories such as Marketing Tool, Xemion, and Top Web Designers. But here’s the rub. These directories have an unfair advantage in the linking scheme of Google. But who said life is fair.
Directories have "muddied the Internet waters." With so many links from so many sites across so many states, it is the equivalent of being a 500-pound linking gorilla. I keep hoping that the next Google dance will place these linking monsters accordingly, but that has yet to happen. Once everyone catches onto this flawed "link ranking" scheme, a search for any term or phrase in Google will provide you nothing but a page full of directories.
Pure Search
This leads to my next point. Say I have an xyz disease (God forbid). If I search "xyz disease nutrition" in Google, I want to find web sites about xyz disease nutrition, or battling xyz disease with proper diet and so on. I don’t want to see a directory full of re-packaged information, filled with ads, newsletters and other useless directory fluff.
I want my search engine to emulate the Library of Congress. Let's say the librarian says, "Books on xyz disease nutrition are located on isle 700b" on row 3. I stroll over to 700b row 3 and pull out a book that systematically lists all the books on 700b, row 3. Wait a second! This isn’t a book about xyz disease nutrition, it's a "directory" or reference book that belongs in the "reference section" of the library.
Are you listening Google?
Maybe Mr. Gates is.
Or better yet maybe Mr. Jobs has a trick or two left up his sleeve.iPod.com today iSearch.com tomorrow.
The Search
I recently purchased a book called "The Search" by John Battelle that explores how Google and its rivals rewrote the rules of business and transformed our culture. What really caught my attention was Chapter 7 titled The Search Economy. It related how a small e-commerce store got yanked by the short-hairs when Google made an unexpected algorithm change in 2003 virtually wiped out their business.
Google did it again in late 2005, and will no doubt do it again and again and again. Rumor has it that it will happen again in March 2006.
Google Giveth, Google Taketh Away
Those of you who are webmasters already know how this happens. Some eager beaver group of Google engineers laid waste to thousands of mom and pop businesses by tweaking Google’s indexing algorithm. These businesses depended on their Google listings for their income and livelihoods. Google giveth and Google taketh away.
Knowing that the Google paradigm will always change puts you ahead of the pack; not putting all your marketing eggs in one basket will keep you there.
Your unpaid or "organic" rankings in search engines are free. But how many times have you heard the axiom "there's no such thing as a free lunch."
Starting to get the picture now?
Google Still Likes Links
I've been getting tons of automated requests for two-way and three-way linking. I can't believe what these people are thinking. The rules are displayed in black and white on Google's web site. Allow me to paraphrase "Build pages for users, not search engines."
Here's a typical email I get every day:
Hello Sir/Madam,I'm mailing you for exchanging three-way link with your site. Though we are accustomed with reciprocal link exchange, the fact is that three-way link is always better than reciprocal link exchange, as all search engines give more attention to three-way links.When search engines can't trace a link back from one site to another it thinks that site is very important so other site is linking to it just like we use google or yahoo in our website.
Do these bozos really believe this?
Fact of the matter is you should link to a website that you believe will be of value to your website viewer’s. That’s it. No schemes, no tricks, no 2, 3, 4, 5 or 6 way linking. Provide your visitors good content and good links. Period.
Vertical Channels and Directories
Web sites like Global Spec (for engineers) and Find Law (for lawyers) are quasi-vertical advertising channels and global directories. Vertical marketing is a great way to target business in the same genre that you practice and participate. It’s also a great way for regional companies to inexpensively obtain entry into new markets or regions.
For web guys like myself, there are similar verticals or directories such as Marketing Tool, Xemion, and Top Web Designers. But here’s the rub. These directories have an unfair advantage in the linking scheme of Google. But who said life is fair.
Directories have "muddied the Internet waters." With so many links from so many sites across so many states, it is the equivalent of being a 500-pound linking gorilla. I keep hoping that the next Google dance will place these linking monsters accordingly, but that has yet to happen. Once everyone catches onto this flawed "link ranking" scheme, a search for any term or phrase in Google will provide you nothing but a page full of directories.
Pure Search
This leads to my next point. Say I have an xyz disease (God forbid). If I search "xyz disease nutrition" in Google, I want to find web sites about xyz disease nutrition, or battling xyz disease with proper diet and so on. I don’t want to see a directory full of re-packaged information, filled with ads, newsletters and other useless directory fluff.
I want my search engine to emulate the Library of Congress. Let's say the librarian says, "Books on xyz disease nutrition are located on isle 700b" on row 3. I stroll over to 700b row 3 and pull out a book that systematically lists all the books on 700b, row 3. Wait a second! This isn’t a book about xyz disease nutrition, it's a "directory" or reference book that belongs in the "reference section" of the library.
Are you listening Google?
Maybe Mr. Gates is.
Or better yet maybe Mr. Jobs has a trick or two left up his sleeve.iPod.com today iSearch.com tomorrow.